Разбираемся с утилитами для бэкапа баз данных. Стратегии резервного копирования и восстановления баз данных SQLBase
Несмотря на то, что в наших предыдущих материалах мы уже касались вопроса резервного копирования баз Microsoft SQL Server, читательский отклик показал необходимость создания полноценного материала с более глубокой проработкой теоретической части. Действительно, выполненные с упором на практические инструкции статьи позволяют быстро настроить резервное копирование, но не объясняют причины выбора тех или иных настроек. Постараемся исправить этот пробел.
Модели восстановления
Перед тем как браться за настройку резервного копирования, следует выбрать модель восстановления. Для оптимального выбора следует оценить требования к восстановлению и критичность потери данных, сопоставив их с накладными расходами на реализацию той или иной модели.
Как известно, база данных MS SQL состоит из двух частей: собственно, базы данных и лога транзакций к ней. База данных содержит пользовательские и служебные данные на текущий момент времени, лог транзакций включает в себя историю всех изменений базы данных за определенный период, располагая логом транзакций мы можем откатить состояние базы на любой произвольный момент времени.
Для использования в производственных средах предлагается две модели восстановления: простая и полная . Существует также модель с неполным протоколированием , но она рекомендуется только как дополнение к полной модели на период крупномасштабных массовых операций, когда нет необходимости восстановления базы на определенный момент времени.
Простая модель предусматривает резервное копирование только базы данных, соответственно восстановить состояние БД мы можем только на момент создания резервной копии, все изменения в промежуток времени между созданием последней резервной копии и сбоем будут потеряны. В тоже время простая схема имеет небольшие накладные расходы: вам необходимо хранить только копии базы данных, лог транзакций при этом автоматически усекается и не растет в размерах. Также процесс восстановления наиболее прост и не занимает много времени.
Полная модель позволяет восстановить базу на любой произвольный момент времени, но требует, кроме резервных копий базы, хранить копии лога транзакций за весь период, для которого может потребоваться восстановление. При активной работе с базой размер лога транзакций, а, следовательно, и размер архивов, могут достигать больших размеров. Процесс восстановления также гораздо более сложен и продолжителен по времени.
При выборе модели восстановления следует сравнить затраты на восстановление с затратами на хранение резервных копий, также следует принять во внимание наличие и квалификацию персонала, который будет выполнять восстановление. Восстановление при полной модели требует от персонала определенной квалификации и знаний, тогда как при простой схеме достаточно будет следовать инструкции.
Для баз с небольшим объемом добавления информации может быть выгоднее использовать простую модель с большой частотой копий, которая позволит быстро восстановиться и продолжить работу, введя потерянные данные вручную. Полная модель в первую очередь должна использоваться там, где потеря данных недопустима, а их возможное восстановление сопряжено со значительными затратами.
Виды резервных копий
Полная копия базы данных - как следует из ее названия, представляет собой содержимое базы данных и часть активного лога транзакций за то время, которое формировалась резервная копия (т.е. сведения обо всех текущих и незавершенных транзакциях). Позволяет полностью восстановить базу данных на момент создания резервной копии.
Разностная копия базы данных - полная копия имеет один существенный недостаток, она содержит всю информацию базы данных. Если резервные копии нужно делать довольно часто, то сразу возникает вопрос неэкономного использования дискового пространства, так как большую часть хранилища будут занимать одинаковые данные. Для устранения этого недостатка можно использовать разностные копии базы данных, которые содержат только изменившуюся со времени последнего полного копирования информацию.
 Обращаем внимание, разностная копия - это данные от момента последнего полного
копирования, т.е. каждая последующая разностная копия содержит в себе данные предыдущей (но при этом они могут быть изменены) и размер копии будет постоянно расти. Для восстановления достаточно одной полной и одной разностной копии, обычно последней. Количество разностных копий следует выбирать исходя из прироста их размера, как только размер разностной копии сравнится с размером половины полной, имеет смысл сделать новую полную копию.
Обращаем внимание, разностная копия - это данные от момента последнего полного
копирования, т.е. каждая последующая разностная копия содержит в себе данные предыдущей (но при этом они могут быть изменены) и размер копии будет постоянно расти. Для восстановления достаточно одной полной и одной разностной копии, обычно последней. Количество разностных копий следует выбирать исходя из прироста их размера, как только размер разностной копии сравнится с размером половины полной, имеет смысл сделать новую полную копию.
Резервная копия журнала транзакций - применяется только при полной модели восстановления и содержит копию журнала транзакций начиная с момента создания предыдущей копии.

Важно помнить следующий момент - копии журнала транзакций никак не связаны с копиями базы данных и не содержат информацию предыдущих копий, поэтому для восстановления базы вам необходимо иметь непрерывную цепочку копий того периода, в течении которого вы хотите иметь возможность откатывать состояние базы. При этом момент последнего успешного копирования должен быть внутри этого периода.
Посмотрим на рисунок выше, если будет утрачена первая копия файла журнала, то вы сможете восстановить состояние базы только на момент полного копирования, что будет аналогично простой модели восстановления, восстановить состояние базы на любой момент времени вы сможете только после следующего разностного (или полного) копирования, при условии, что цепочка копий журналов начиная с предшествующего копированию базы и далее будет непрерывна (на рисунке - от третьего и далее).
Журнал транзакций
Для понимания процессов восстановления и назначения разных видов резервных копий следует более подробно рассмотреть устройство и работу журнала транзакций. Транзакция - это минимально возможная логическая операция, которая имеет смысл и может быть выполнена только полностью. Такой подход обеспечивает целостность и непротиворечивость данных при любых ситуациях, так как промежуточное состояние операции недопустимо. Для контроля над любыми изменениями в базе предназначен журнал транзакций.
При выполнении любой операции в журнал транзакций добавляется запись о начале транзакции, каждой записи присваивается уникальный номер (LSN) из неразрывной последовательности, при любом изменении данных в журнал вносится соответствующая запись, а после завершения операции в журнале появляется отметка о закрытии (фиксации) транзакции.
 При каждом запуске система анализирует журнал транзакций и откатывает все незафиксированные транзакции, одновременно с этим происходит накат изменений, которые зафиксированы в журнале, но не были записаны на диск. Это дает возможность использовать кэширование и отложенную запись, не опасаясь за целостность данных даже при отсутствии систем резервного питания.
При каждом запуске система анализирует журнал транзакций и откатывает все незафиксированные транзакции, одновременно с этим происходит накат изменений, которые зафиксированы в журнале, но не были записаны на диск. Это дает возможность использовать кэширование и отложенную запись, не опасаясь за целостность данных даже при отсутствии систем резервного питания.
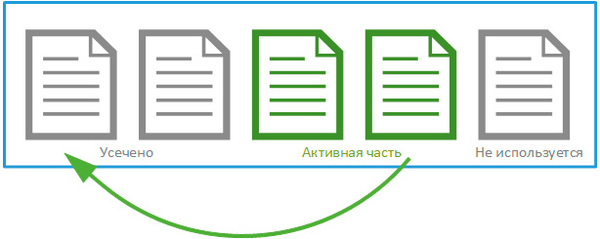
Та часть журнала, которая содержит активные транзакции и используется для восстановления данных называется активной частью журнала. Она начинается с номера, который называется минимальным номером восстановления (MinLSN).
В простейшем случае MinLSN - это номер записи первой незавершенной транзакции. Если посмотреть на рисунок выше, то открыв синюю транзакцию мы получим MinLSN равную 321, после ее фиксации в записи 324, номер MinLSN изменится на 323, что будет соответствовать номеру зеленой, еще не зафиксированной, транзакции.
На практике все немного сложнее, например, данные закрытой синей транзакции могут быть еще не сброшены на диск и перемещение MinLSN на 323 сделает восстановление этой операции невозможной. Для того, чтобы избежать таких ситуации было введено понятие контрольной точки. Контрольная точка создается автоматически при наступлении следующих условий:
- При явном выполнении инструкции CHECKPOINT. Контрольная точка срабатывает в текущей базе данных соединения.
- При выполнении в базе данных операции с минимальной регистрацией, например, при выполнении операции массового копирования для базы данных, на которую распространяется модель восстановления с неполным протоколированием.
- При добавлении или удалении файлов баз данных с использованием инструкции ALTER DATABASE.
- При остановке экземпляра SQL Server с помощью инструкции SHUTDOWN или при остановке службы SQL Server (MSSQLSERVER). И в том, и в другом случае будет создана контрольная точка каждой базы данных в экземпляре SQL Server.
- Если экземпляр SQL Server периодически создает в каждой базе данных автоматические контрольные точки для сокращения времени восстановления базы данных.
- При создании резервной копии базы данных.
- При выполнении действия, требующего отключения базы данных. Примерами могут служить присвоение параметру AUTO_CLOSE значения ON и закрытие последнего соединения пользователя с базой данных или изменение параметра базы данных, требующее перезапуска базы данных.
В зависимости от того, какое событие произошло раньше, MinLSN будет присвоено значение либо номера записи контрольной точки, либо начала самой старой незавершенной транзакции.
Усечение журнала транзакций
Журнал транзакций, как и любой журнал, требует периодической очистки от устаревших записей, иначе он разрастется и займет все доступное место. Учитывая, что при активной работе с базой размер лога транзакций может значительно превышать размер базы, то этот вопрос актуален для многих администраторов.
Физически файл журнала транзакций является контейнером для виртуальных журналов, которые последовательно заполняются по мере роста лога. Логический журнал, содержащий запись MinLSN является началом активного журнала, предшествующие ему логические журналы являются неактивными и не требуются для автоматического восстановления базы.
 Если выбрана простая модель восстановления, то при достижении логическими журналами размера равного 70% физического файла происходит автоматическая очистка неактивной части журнала, т.н. усечение. Однако это не приводит к уменьшению физического файла журнала, усекаются только логические журналы, которые после этой операции могут использоваться повторно.
Если выбрана простая модель восстановления, то при достижении логическими журналами размера равного 70% физического файла происходит автоматическая очистка неактивной части журнала, т.н. усечение. Однако это не приводит к уменьшению физического файла журнала, усекаются только логические журналы, которые после этой операции могут использоваться повторно.
Если количество транзакций велико и к моменту достижения 70% размера физического файла не окажется неактивных логических журналов, то размер физического файла будет увеличен.
 Таким образом файл лога транзакций при простой модели восстановления будет расти согласно активности работы с базой до тех пор, пока не будет надежно вмещать всю активную часть журнала. После чего его рост прекратится.
Таким образом файл лога транзакций при простой модели восстановления будет расти согласно активности работы с базой до тех пор, пока не будет надежно вмещать всю активную часть журнала. После чего его рост прекратится.
При полной модели неактивную часть журнала нельзя усечь до тех пор, пока она полностью не попадет в резервную копию. Усечение журнала производится при условии, что выполнена резервная копия журнала транзакций, после чего была создана контрольная точка.
Неправильная настройка резервного копирования журнала транзакций при полной модели способно привести к неконтролируемому росту файла журнала, что часто составляет проблему для неопытных администраторов. Также часто попадаются советы по ручному усечению журнала транзакций. При полной модели восстановления делать этого не следует категорически, так как тем самым вы нарушите целостность цепочки копий журнала и сможете восстановить базу только на момент создания копий, что будет соответствовать простой модели.
В этом случае самое время вспомнить то, о чем мы говорили в начале статьи, если затраты на полную модель превышают затраты на восстановление следует отдать предпочтение простой модели.
Простая модель восстановления
Теперь, после получения необходимого минимума знаний, можно перейти к более подробному рассмотрению моделей восстановления. Начнем с простой. Допустим, на момент сбоя у нас имеется одна полная и две разностные копии:
 Резервное копирование выполнялось раз в сутки и последняя копия была создана ночью с 21-го на 22-е. Сбой происходит вечером 22-го до создания очередной копии. В этом случае нам потребуется последовательно восстановить полную и последнюю разностные копии, при этом данные за последний рабочий день будут утеряны. Если по каким-либо причинам копия от 21-го также окажется повреждена, то мы можем восстановить предыдущую копию, потеряв еще день работы, в тоже время повреждение копии за 20-е число никак не помешает успешно восстановить данные на вечер 21-го, при наличии соответствующей копии.
Резервное копирование выполнялось раз в сутки и последняя копия была создана ночью с 21-го на 22-е. Сбой происходит вечером 22-го до создания очередной копии. В этом случае нам потребуется последовательно восстановить полную и последнюю разностные копии, при этом данные за последний рабочий день будут утеряны. Если по каким-либо причинам копия от 21-го также окажется повреждена, то мы можем восстановить предыдущую копию, потеряв еще день работы, в тоже время повреждение копии за 20-е число никак не помешает успешно восстановить данные на вечер 21-го, при наличии соответствующей копии.
Полная модель восстановления
Рассмотрим аналогичную ситуацию, но с применением полной модели восстановления. Резервные копии у нас также делаются ежесуточно, по принципу полная + разностные, а также несколько раз в сутки копируется лог транзакций.
 Процесс восстановления в этом случае будет более сложен. Прежде всего потребуется создать вручную резервную копию заключительного фрагмента журнала (показана красным), т.е. часть журнала с момента прошлого создания копии и до аварии.
Процесс восстановления в этом случае будет более сложен. Прежде всего потребуется создать вручную резервную копию заключительного фрагмента журнала (показана красным), т.е. часть журнала с момента прошлого создания копии и до аварии.
Если этого не сделать, то восстановить базу можно будет только до состояния на момент создания последней копии журнала транзакций.
При этом повреждение файла копии журнала за предыдущий день не помешает нам восстановить актуальное состояние базы, но ограничит нас моментом создания последней копии, т.е. текущими сутками.
Затем последовательно восстанавливаем полную и разностную копию и цепочку копий журнала, созданную после последнего резервного копирования, последней восстанавливаем копию заключительного фрагмента журнала, что даст нам возможность восстановить базу прямо на момент аварии или произвольный, предшествовавший ему.
Если последняя разностная копия будет повреждена, то в случае с простой моделью это приведет к потере еще одного рабочего дня, полная модель позволяет восстановить предпоследнюю копию, после чего нужно будет восстановить всю цепочку копий лога транзакций от момента предпоследней копии и до сбоя. Глубина восстановления зависит только от глубины непрерывной цепочки логов.
С другой стороны, если одна из копий лога транзакций будет повреждена, скажем, предпоследняя, то восстановить данные мы сможем только на момент последней резервной копии + период в неповрежденной цепочке копий журналов. Например, если журналы делались в 12, 14 и 16 часов и поврежден журнал, созданный в 14 часов, то располагая суточной копией мы сможем восстановить базу до момента окончания непрерывной цепочки, т.е. до 12 часов.
Теги:
Для целостности ИТ инфраструктуры крайне важно обеспечить правильное резервное копирование базы данных. Как правило, при этом важно соблюдать требования политики безопасности. Реализованные на базе плагинов для СУБД передовые решения Bacula Systems позволят любой компании-пользователю Bacula Enterprise быстро и надежно производить резервное копирование баз данных.
Когда важна простота и скорость, самым верным решением для системного администратора, работающего в условиях жестких временных рамок, становится использование инструментов Bacula Systems. Вам не потребуются особые знания, для того чтобы позаботиться о сохранности данных и метаданных, включая данные о пользователях, правах, ролях и т.д. В то же время пользователю доступны широкие возможности по индивидуальной настройке ПО, обеспечивающие необходимую гибкость при работе в наиболее сложных профессиональных средах.
Резервное копирование базы данных Oracle
Упрощает процедуры резервного копирования и восстановления баз данных Oracle. Администраторы БД Oracle могут воспользоваться командами RMAN с целью более простого и удобного резервного копирования базы данных. Помимо скорости и простоты, плагин для Oracle существенно оптимизирует прочие важные функции, в том числе восстановление БД на любой момент времени, а также фильтр объектов во время резервного копирования и восстановления. Все эти возможности доступны при использовании любого из двух методов резервного копирования, а именно “Dump” метода и метода восстановление до заданной контрольной точки (PITR) с помощью тесной интеграции плагина с диспетчером восстановления Oracle RMAN.
Плагин также задействует RMAN API sbt, что позволяет исключать запись файлов в первую очередь на локальные диски. И в режиме “Dump”, и в режиме RMAN плагин создает резервную копию значимой информации, что является бест-практикой администрирования Oracle DB. Как правило, методы “Dump” и RMAN PITR используются совместно для резервного копирования одного и того же кластера.

Повышение эффективности инкрементального и дифференциального резервного копирования Oracle
Плагин для Oracle от Bacula Systems использует многие компоненты RMAN, включая функцию отслеживания изменений для повышения производительности резервного копирования путем записи блоков из каждого файла данных в файл отслеживания изменений. Если функция отслеживания изменений активирована, утилита RMAN использует файл отслеживания изменений для идентификации измененных блоков для выполнения инкрементального копирования, что позволяет избегать необходимости сканировать каждый блок в файле данных.
Восстановление данных Oracle
Как показано на рисунке ниже, плагин для Oracle позволяет восстанавливать БД с помощью утилит RMAN или используя метод Dump.

Поддерживаемые версии платформы Oracle для бэкапа
Плагин доступен для 32 и 64-битной версии Linux и совместим с БД Oracle версий 10.x, 11.x.
Резервное копирование и восстановление PostgreSQL
Был разработан с целью упростить процедуры резервного копирования и восстановления кластеров БД PostgreSQL. Администратору не нужно знать внутренние методы резервного копирования PostgreSQL или процедуры написания сложных скриптов. Плагин автоматически создает резервную копию значимой информации, например, конфигурации БД, определений пользователей, табличных пространств. Плагин для PostgreSQL поддерживает два метода создания резервных копий “Dump” и PITR.
Используя уникальную технологию включения последних данных Late Data Inclusion (LDI) от компании Bacula Systems, данный плагин эффективно захватывает данные вплоть до момента завершения создания бэкапа, тем самым, сводя к минимуму риск их потери. Это является преимуществом плагина по сравнению с решениями других вендоров.
Горячее резервное копирование базы данных PostgreSQL
Плагин Bacula Systems для PostgreSQL также позволяет администратору БД создавать бэкапы серверов PostgreSQL в режиме «горячего резервного копирования» с резервным копированием WAL файлов.
Восстановление PostgreSQL

Содержимое кластера

Содержимое базы данных
Поддерживаемые версии платформы PostgreSQL для бэкапа
Резервное копирование базы данных PostgreSQL доступно используется под 32 и 64-битные версии Linux и поддерживает PostgreSQL версий: 8.4, 9.0, 9.1 и 9.2. Работает на базе ПО Bacula Enterprise версии 6.0.6 и выше.
Резервное копирование и восстановление базы данных MySQL
Был разработан с целью упростить процедуры резервного копирования и восстановления серверов MySQL. Администратору не нужно знать внутренние методы резервного копирования MySQL или процедуры написания сложных скриптов. Плагин конфигурируем и автоматически создает бэкапы значимой информации, например, конфигурации БД и определений пользователей. Плагин для MySQL поддерживает два метода создания резервных копий “Dump” и “Binary”.
Возможность выбора методики резервного копирования базы данных MySQL
Позволяет администратору выбирать метод Dump или Binary для более быстрого резервного копирования и создания больших по объему бэкапов. Плагин для MySQL обрабатывает лог-файлы MySQL при использовании функции создания PITR бэкапов.
Восстановление данных БД MySQL

Восстановление единичной БД MySQL

Поддерживаемые версии платформы MySQL для бэкапа
Резервное копирование и восстановление базы данных MySQL доступно под 32 и 64-битные версии Linux и поддерживает MySQL версий 4.0.x, 4.1.x, 5.0.x, 5.5.x, 5.6.x.
Резервное копирование базы данных SQL Server
VSS плагин – один из двух способов резервного копирования базы SQL Server с помощью ПО Bacula Systems. Резервное копирование базы данных SQL Server через VSS плагин разработано для бэкапа нескольких специфических компонентов Windows, в частности базы SQL Server. Плагин Bacula Enterprise VSS существенно упрощает создание резервных копий БД SQL Server.
Быстрый и простой способ восстановления базы данных SQL Server
VSS плагин способен восстанавливать либо master, либо прочие инстансы БД. Все БД, за исключением master, могут быть восстановлены во время работы MS SQL. VSS плагин также может быть использован совместно с процессом перемещения БД MS SQL.

Дерево SQL сервера во время восстановления

Перемещенная БД
Поддерживаемые версии резервного копирования базы данных SQL
Резервное копирование базы данных SQL осуществляется под Windows 2003 SP1 и выше, Windows 2008 R1 и Windows 2008 R2.
Резервное копирование базы данных SQL — расширенные возможности
– это современное решение для создания резервных копий множества БД MS SQL, позволяющий:
- Осуществлять полное резервное копирование, при котором сохраняются файлы БД и лог-файлы транзакций, что позволяет избегать отказа системы хранения данных.
- При дифференциальном резервном копировании сохраняется только те данные, которые были изменены с момента создания последнего полного бэкапа. Плагин Bacula Enterprise для SQL Server включает интегрированные опции по повышению класса резервного копирования с дифференциального до полного если это необходимо.
- Создание инкрементальных бэкапов посредством резервного копирования логов транзакций. В случае конфигурации по соответствующей модели, данный метод позволяет использовать режим PITR.
- Резервное копирование master-БД для создания резервной копии информации о конфигурации MS SQL.
Мощный инструмент восстановления баз данных SQL
Плагин Bacula Enterprise для SQL способен восстанавливать данные несколькими способами, в том числе с использованием восстановления до контрольной точки PITR. В таком случае процесс восстановления предполагает следующие сценарии:
- Восстановление файлов на диск
- Восстановление исходной БД
- Восстановление БД с новым именем
- Восстановление БД с новым именем и перемещением файлов

Модель создания бэкапа БД “с полным и неполным протоколированием”
Поддерживаемые версии платформы MS SQL для бэкапа
Резервное копирование базы данных MS SQL возможно под Windows 2003 R2, Windows 2008 R2, Windows 2012 и для MS SQL Server 2005, 2008 и 2014.
Интересует резервное копирование базы данных с Bacula Enterprise и квалифицированная поддержка? Смотрите видео.
Одной из важнейших задач, которую должен постоянно выполнять администратор баз данных - это осуществление резервного копирования. Если что-то пойдет не так, то это задача именно администратора баз данных восстановить сервер и запустить его как можно быстрее. Потеря производительности или, что хуже того, потеря данных, может очень дорого обойтись предприятию.
При желании иметь актуальную резервную копию БД, возникает желание использовать конфигурацию дисков RAID, которая обеспечивает создание зеркала с целью защиты данных, но это не панацея. Массивы RAID являются только первой ступенью в деле обеспечения защиты данных от потери. В зависимости от конфигурации массива RAID, один или даже несколько жестких дисков должны выйти из строя, прежде чем произойдет безвозвратная потеря данных. Кроме того, использование дисков «горячей» замены и горячего резерва может быть использовано для того, чтобы сервер продолжал работать без отключения даже в случае выхода из строя жесткого диска. Ключевая вещь, которую вы должен понимать АБД, это то, что массивы RAID могут защитить данные в случае выхода из строя жестких дисков. А что произойдет, если будет ЧП (пожар, потоп, ограбление и т.д.)? Файлы базы данных окажутся, повреждены в результате ошибки программного обеспечения или аппаратного сбоя? Ну и наконец, что будет, если пользователь (или сам АБД) удалит по ошибки данные, которые вдруг потребуются в дальнейшем? Конфигурация RAID не сможет помочь в этих случаях.
Самое главное - администратор может всегда заменить сервер, но данные этого сервера восстановить чрезвычайно трудно, иногда просто невозможно.
Рассмотрим некоторые типы резервного копирования баз данных.
Сервер SQL поддерживает три вида резервного копирования: полное (Full), разностное или дифференциальное (Differential) и копирование журнала (Log). В дополнение к трем основным видам резервного копирования, которые работают со всей базой данных в целом, есть также несколько дополнительных типов резервного копирования, которые используются для копирования одного файла или группы файлов.
Полное резервное копирование (Full) - создает полную резервную копию всех экстентов базы данных. Если АБД будет восстанавливать базу данных, используя для этого полную резервную копию, потребуется только самый последний созданный им экземпляр. Однако, полное резервное копирование - самый медленный тип резервного копирования.
Дифференциальное резервное копирование (Differential) - создает резервную копию только тех экстентов, которые были изменены с момента последнего полного копирования. Если АБД будет восстанавливать базу данных, используя дифференциальную резервную копию, ему потребуется последняя полная резервная копия и последняя созданная им дифференциальная резервная копия. Дифференциальное резервное копирование осуществляется гораздо быстрее, но требует больше времени на восстановление, так как требует применение, как полной резервной копии, так и дифференциальной резервной копии.
Резервная копия журнала - создает резервную копию журнала транзакций с момента последней полной резервной копии или предыдущей копии журнала транзакций. АБД потребуется (или не потребуется) создавать резервные копии журнала транзакций в зависимости от используемой им модели восстановления. Если он будет восстанавливать базу данных, используя полное резервное копирование и копирование журнала транзакций, для восстановления ему потребуется последняя полная резервная копия и все (по порядку) резервные копии журнала транзакций.
Следует заметить, что резервное копирование обычно осуществляется при работающей (on-line) базе данных. Этот процесс называется «размытое резервное копирование», потому что он выполняется на протяжении некоторого отрезка времени. Если в процессе резервного копирования экстентов базы данных происходят какие-либо изменения, процесс копирования, безусловно, продолжается. Для поддержания целостности, полное и разностное резервное копирование фиксирует ту часть файла журнала транзакций, которая соответствует времени от начала и до конца резервного копирования.
Сервер SQL может выполнять резервное копирование в файл, расположенный на жестком диске, на сетевом диске, на устройстве с магнитной лентой.
Все изменения, сделанные в базе данных, обязательно фиксируются в журнале транзакций. В случае аварии (такой, как отключение электроэнергии или «синий» экран) журнал транзакций может быть использован для восстановления изменений базы данных. Кроме того, контрольные точки используются для записи всех страниц оперативной памяти на жесткий диск, тем самым уменьшая время, необходимое для восстановления базы данных. Итак, если в контрольной точке все страницы с данными записываются на жесткий диск, зачем нам необходимо хранить информацию о транзакциях? Отвечая на этот вопрос, нам придется говорить о моделях восстановления.
Каждая база данных, запущенная на сервере SQL может придерживаться одной из трех моделей восстановления: Полной (Full), Регистрации пакетных операций (Bulk_Logged) и Простой (Simple).
Модель полного восстановления предоставляет наибольшее число возможностей в случае повреждения данных. Если все транзакции заносятся в журнал, и используется режим полного восстановления, транзакции сохраняются в журнале до тех пор, пока не будет создана их резервная копия. Как только будет осуществлено резервное копирование базы данных, дисковое пространство, использовавшееся для хранения информации о транзакциях, становится свободным и затем может быть использовано для ведения журнала новых транзакций. Так как все транзакции вносятся в резервную копию, полное резервное копирование делает возможным восстановление базы данных в «заданной точке времени», используя только те транзакции, которые имели место до этого момента времени. Например, мы можем провести восстановление, используя полную резервную копию, а затем восстановить все копии журнала транзакций до определенного момента, прежде чем какие-то важные данные были удалены.
Если модель полного восстановления отслеживает все изменения, сделанные в базе данных, и позволяет нам восстанавливать все транзакции к любому моменту времени, то возникает вопрос - почему бы всегда не использовать эту модель? Так как все операторы должны при этом фиксироваться полностью, на выходе может получиться достаточно «тяжелый» файл журнала. Кроме того, такие команды как BULK INSERT будут замедлять работу сервера, так как все выполняемые ими изменения должны вноситься в журнал.
Модель регистрации пакетных операций (bulk_logged) достаточно похожа на модель полного восстановления с некоторые добавлениями и преимуществами. Как и в полной модели восстановления, в модели регистрации пакетных операций также фиксируются все операторы UPDATE, DELETE и INSERT. Однако, для определенных команд, в данной модели фиксируется лишь то, что операция имела место. Это верно для таких команд как BULK INSERT, bcp, CREATE INDEX, SELECT INTO, WRITETEXT и UPDATETEXT. Модель регистрации пакетных операций похожа на модель полного восстановления тем, что не использует повторно (не перезаписывает) пространство журнала до тех пор, пока не будет произведено резервное копирование всех транзакций.
В отличие от модели полного восстановления, если журнал транзакций содержал пакетные операторы, то вы не сможете осуществить восстановление на конкретный момент времени, вы должны восстанавливать ее только на конец всего журнала. Также резервная копия журнала базы данных может оказаться значительной по размерам, потому что в модели регистрации пакетных операций процесс резервного копирования журнала должен копировать все экстенты, которые были изменены.
Преимущества данной модели состоят в том, что файлы журнала транзакций для баз данных могут быть меньше, если вы используете много пакетных операторов. Кроме того, пакетные операторы выполняются быстрее, так как фиксироваться должен только факт, что выполнение этого оператора имело место, а не само изменение в базе данных.
Простая модель восстановления. В отличие от полной и модели регистрации пакетных операций, простая модель восстановления не использует резервное копирование журнала транзакций. В данной модели журналы транзакций часто усекаются (усечение - это процесс удаления старых транзакций из журнала) автоматически. Модель простого восстановления может использовать полное и разностное резервное копирование.
база данные администрирование документоведение
Как вы знаете, все важные данные ваших сайтов, их настройки, статьи, комментарии и другая информация хранятся в базе данных. Потеря этой информации может иметь очень тяжелые последствия для проекта. Поэтому важно своевременно делать резервные копии базы данных mysql. Также эти копии могут быть очень полезными при переносе проекта на другой сервер.
В этой инструкции мы рассмотрим как выполняется резервное копирование mysql или mariadb базы данных, а также как восстановить информацию в базе из копии. Кроме того, мы разберем как настроить автоматическое создание копий через определенный промежуток времени.
Все что вам нужно для резервного копирования mysql - это доступ к серверу с операционной системой Linux, на котором установлен сервер баз данных, а также имя базы данных и параметры доступа к ней.
Для экспорта информации из базы данных в формате SQL можно использовать утилиту mysqldump. Вот ее синтаксис:
$ mysqldump опции имя_базы [имя_таблицы] > файл.sql
По умолчанию утилита будет выводить все в стандартный вывод, поэтому нам нужно перенаправить эти данные в файл, что мы и делаем с помощью оператора ">". Опции указывают параметры аутентификации и работы, а имя базы и таблицы - данные которые нужно экспортировать. Теперь рассмотрим кратко опции, которые будем использовать:
- -A - копировать все таблицы из всех баз данных;
- -i - записывать дополнительную информацию в комментариях;
- -c - использовать имена колонок для инструкции INSERT;
- -a - включать все возможные опции в инструкцию CREATE TABLE;
- -k - отключает первичные ключи на время копирования;
- -e - использовать многострочный вариант инструкции INSERT;
- -f - продолжить даже после ошибки;
- -h - имя хоста, на котором расположен сервер баз данных, по умолчанию localhost;
- -n - не писать инструкции для создания базы данных;
- -t - не писать инструкции для создания таблиц;
- -d - не записывать данные таблиц, а только их структуру;
- -p - пароль базы данных;
- -P - порт сервера баз данных;
- -Q - брать все имена таблиц, баз данных, полей в кавычки;
- -X - использовать синтаксис XML вместо SQL;
- -u - пользователь, от имени которого нужно подключаться к базе данных.
В большинстве случаев нам достаточно задать имя пользоваться, пароль, а также имя базы данных. Дальше рассмотрим примеры работы с утилитой. Например самая простая команда экспорта базы данных:
mysqldump -u имя_пользователя -p имя_базы > data-dump.sql
Вам нужно будет ввести пароль пользователя базы данных и больше ничего команда не выведет, поскольку мы отправили все данные в файл, но вы можете посмотреть информацию о резервной копии с помощью такой команды:
head -n 5 data-dump.sql

Но если во время создания копии возникнут какие-либо ошибки, они будут выведены на экран и вы сразу о них узнаете. Более сложный вариант, это выполнить резервное копирование mysql с другого хоста, если у вас есть к нему доступ:
mysqldump -h хост -P порт -u имя_пользователя -p имя_базы > data-dump.sql
Копирование таблицы mysql может быть выполнено простым добавлением имени таблицы в конец строки:
mysqldump -u имя_пользователя -p имя_базы имя_таблицы > data-dump.sql
Также, чтобы выполнять автоматическое резервное копирование базы mysql может понадобиться сразу задать пароль, для этого указывайте его сразу после опции -p, без пробела:
mysqldump -u имя_пользователя -pпароль имя_базы > data-dump.sql

Мы можем делать бэкап вручную время от времени, но это не совсем удобно, поскольку есть другие важные дела. Поэтому используем планировщик cron, чтобы автоматизировать процесс. Тут есть два способа более простой, и более сложный, но точный. Допустим, нам нужно создавать резервную копию каждый день, тогда просто создайте скрипт в папке /etc/cron.daily/ со следующим содержимым:
sudo vi /etc/cron.daily/mysql-backup
!/bin/bash
/usr/bin/mysqldump -u имя_пользователя -pпароль имя_базы > /backups/mysql-dump.sql

Папку /backups/mysql-dump.sql нужно заменить на свою папку для резервных копий. Осталось дать скрипту права на выполнение:
chmod ugo+x /etc/cron.daily/mysql-backup
Добавьте в открывшейся файл такую строку и сохраните изменения:
30 2 * * * /usr/bin/mysqldump -u имя_пользователя -pпароль имя_базы > /backups/mysql-dump.sql
Команда будет выполняться каждый день, в 2:30, это удобно, поскольку ночью обычно меньше нагрузка на сервер. Как вы поняли, первое число - это минуты, второе - часы, третье день, дальше неделя и месяц. Звездочка значит, что этот параметр не имеет значения.
Восстановление из резервной копии
Восстановить резервную копию mysql или mariadb из существующего SQL файла тоже очень просто. Поскольку использовался синтаксис sql мы просто можем выполнить все команды с помощью стандартного клиента mysql.
Сначала нужно создать новую базу данных. Для этого авторизуйтесь на mysql сервере с правами суперпльзователя:
mysql -u root -p
Затем создайте новую базу данных, например, с именем new_database, если база данных уже существует, то этого делать не нужно:
mysql> CREATE DATABASE new_database;

mysql -u пользователь -p база_данных < data-dump.sql

Для экспорта мы направляли данные стандартного вывода в файл, а здесь происходит обратная операция, данные из файла направляются на стандартный ввод программы. Успешно выполненная команда ничего не выведет, и чтобы убедиться что все прошло успешно, просто посмотрите содержимое базы.
Выводы
Теперь вы знаете как выполняется копирование базы данных mysql, а также как восстановить скопированную информацию. Мы рассмотрели все возможные опции mysqldump чтобы вы могли настроить утилиту так, как вам нужно. Резервное копирование базы данных mysql это очень важный момент и в определенной ситуации может сохранить много времени, поэтому обязательно настройте у себя на сервере!
Резервное копирование базы данных - это такая штука, которую вечно приходится настраивать для уже работающих проектов прямо на «живых» production-серверах.
Подобная ситуация легко объяснима. В самом начале любой проект еще пуст и там просто нечего копировать. В фазе бурного развития головы немногочисленных разработчиков заняты исключительно прикручиванием фишек и рюшек, а также фиксом критических багов с дедлайном «позавчера». И только когда проект «взлетит», приходит осознание, что главная ценность системы - это накопленная база данных, и её сбой станет катастрофой.
Эта обзорная статья - для тех, чьи проекты уже достигли этой точки, но жареный петух ещё не клюнул.
1. Копирование файлов базы
Базу данных MySQL можно скопировать, если временно выключить MySQL-сервер и просто скопировать файлы из папки /var/lib/mysql/db/ . Если сервер не выключить, по очевидным причинам вероятна потеря и порча данных. Для больших нагруженных баз эта вероятность близка к 100%. Кроме того, при первом запуске с «грязной» копией базы данных MySQL-сервер начнет процесс проверки всей базы, который может затянуться на часы.В большинстве «живых» проектов регулярное выключение сервера БД на длительное время неприемлемо. Для решения этой проблемы применяется трюк, основанный на снэпшотах файловой системы. Снэпшот - это что-то вроде «фотографии» файловой системы на определенный момент времени, сделанный без реального копирования данных (и потому быстро). Аналогичным образом работает «ленивое копирование» объектов во многих современных языках программирования.
Общая схема действий такова: блокируются все таблицы, сбрасывается файловый кэш БД, делается снэпшот файловой системы, разблокируются таблицы. После этого файлы спокойно копируются из снэпшота, после чего он уничтожается. «Блокирующая» часть такого процесса занимает время порядка секунд, что уже терпимо. В качестве расплаты на какое-то время, пока «жив» снэпшот, снижается производительность файловых операций, что в первую очередь бьет по скорости операций записи в базу.
Некоторые файловые системы, например, ZFS, поддерживают снятие снэпшотов нативно. Если вы не пользуетесь ZFS, но на вашем сервере стоит менеджер томов LVM, вы также сможете скопировать базу MySQL через снэпшот . Наконец, под *nix можно воспользоваться драйвером снэпшотов R1Soft Hot Copy , но этот способ не заработает в контейнере openvz ().
Для баз MyISAM существует официальная бесплатная утилита mysqlhotcopy , которая «правильно» копирует файлы баз MyISAM без остановки сервера. Существует аналогичная утилита для InnoDB , но она платная, хотя и возможностей в ней больше.
Копирование файлов - самый быстрый способ перебросить базу данных целиком с одного сервера на другой.
2. Копирование через текстовые файлы
Для того, чтобы считать в бэкап данные из production-базы, необязательно дергать файлы. Можно выбрать данные запросом и сохранить их в текстовый файл. Для этого используется SQL-команда SELECT INTO OUTFILE и парная ей LOAD DATA INFILE . Выгрузка производится построчно (можно отобрать для сохранения только нужные строки, как в обычном SELECT). Структура таблиц нигде не указывается - об этом должен заботиться программист. Он также должен позаботиться о включении команд SELECT INTO OUTFILE в транзакцию, если это необходимо для обеспечения целостности данных. На практике SELECT INTO OUTFILE используется для частичного бэкапа очень больших таблиц, которые нельзя скопировать никаким другим образом.В большинстве случаев намного более удобна созданная Игорем Романенко утилита mysqldump . Утилита mysqldump формирует файл, содержащий все SQL-команды, необходимые для полного восстановления БД на другом сервере. Отдельными опциями можно добиться совместимости этого файла с практически любой СУБД (не только MySQL), кроме того, существует возможность выгрузки данных в форматах CSV и XML. Для восстановления данных из таких форматов существует утилита mysqlimport .
Утилита mysqldump консольная. Существуют её надстройки и аналоги, позволяющие управлять бэкапом через веб-интерфейс, например, украинская тулза Sypex Dumper (их представитель zapimir есть на хабре).
Недостатки универсальных утилит бэкапа в текстовые файлы - это относительно невысокая скорость работы и отсутствие возможности делать инкрементные бэкапы.
3. Инкрементные бэкапы
Традиционно рекомендуют держать 10 бэкапов: по одному на каждый день недели, а также бэкапы двухнедельной, месячной и квартальной давности - это позволит достаточно глубоко откатиться в случае порчи каких-либо данных.Храниться бэкапы должны точно не на том же диске, что и живая база, и не на том же сервере. На случай пожаров и прочих катаклизмов лучше всего арендовать пару юнитов в соседнем дата-центре.
Эти требования могут стать проблемой для больших баз. Прокачка бэкапа 100-гигабайтной базы по 100-мбитной сети займет часа три, на которые полностью забьет канал.
Частично решить эту проблему позволяют инкрементные бэкапы, когда полный бэкап делается, скажем, только по воскресеньям, а в остальные дни пишутся только данные, добавленные или измененные за прошедшие сутки. Сложность в том, как выявить эти самые «данные, изменившиеся за сутки».
Здесь практически вне конкуренции система Percona XtraBackup , которая содержит модифицированный движок InnoDB, анализирует двоичные логи MySQL и вытаскивает из них необходимую информацию. Почти такими же возможностями обладает платная InnoDB Hot Backup, упомянутая выше.
Общая проблема с любыми бэкапами в том, что они всегда отстают. В случае фатального сбоя основного сервера восстановить систему можно будет только с некоторым «откатом» по времени, что очень и очень разочарует её пользователей. Если в системе так или иначе были затронуты финансовые потоки, подобный «откат» может в прямом смысле влететь в копеечку.