Smart hdd расшифровка. Оценка технического состояния жестких дисков с использованием технологии S.M.A.R.T
Оснащаются специальной микропрограммой самодиагностики S.M.A.R.T. (self-monitoring, analysis and reporting technology). Эта технология позволяет отслеживать состояние HDD, анализировать его работу и предсказывать выход из строя. «СМАРТ» отслеживает свыше 40 параметров, результат по каждому из которых вносится в специальную таблицу. Анализ статистики S.M.A.R.T. позволяет обнаружить уязвимые места и предсказать выход жесткого диска из строя.
Эта статья расскажет о том, как посмотреть SMART жесткого диска, расшифровать его показания, и каким параметрам следует уделить повышенное внимание. Стоит отметить, что информация подается структурированно, но для извлечения из нее данных требуется специальное ПО.
Как посмотреть S.M.A.R.T. жесткого диска. Расшифровка параметров.
Чтобы проверить параметры «СМАРТ», нужно чтобы эта функция была включена в системе. Это актуально для компьютеров, выпущенных до 2010 года. В них в BIOS присутствует опция HDD S.M.A.R.T. Capability, включение которой позволяет полноценно отслеживать «СМАРТ». В новых ПК вопрос «как включить S.M.A.R.T. на жестком диске?» неактуален – все включено по умолчанию.
Для просмотра параметров состояния HDD нужна специальная утилита для работы с ЖД (Victoria, HD Tune, HDD Scan) или комплексные диагностические программы (Everest или ее «наследница» Aida64). Они позволяют вывести таблицу в легком для понимания виде.
Проанализируем параметры на примере «Виктории». Как видно из изображения, жесткий диск (в данном случае это Seagate на 200 Гб с устаревшим интерфейсом IDE) поддерживает не все команды «СМАРТ» и фиксирует часть параметров.
В заглавии таблицы можно увидеть ID параметра, его имя, значения VAL, Wrst, Tresh и Raw, а также оценочную графу Health.
- ID – номер параметра в общем списке анализируемых критериев.
- VAL – текущее его значение в абстрактных единицах (обычно процентах от идеального показателя).
- Wrst – наихудшее значение, которого винчестер когда-либо достигал.
- Tresh – условный порог для значения VAL, по достижении которого система уведомляет о надвигающейся «смерти» HDD.
- RAW – выражение параметра VAL в численном формате (количество часов наработки/сбоев/ошибок/багов).
Параметр Health позволяет оценить состояние HDD людям, незнакомым с тонкостями компьютерного железа или английским языком. Он присваивает привычную оценку от 1 до 5 баллов каждому из них.
При анализе состояния жесткого диска следует обратить внимание на VAL (сравнивая с графой Tresh) и RAW (для объективной оценки). В приведенном примере видно, что ЖД пережил много ошибок чтения (у Seagate, Fujitsu и Samsung на эту графу можно не смотреть – сюда фиксируются все ошибки) и имеет большое время работы (параметр 9). Из таблицы видно, что число коррекций аппаратных ошибок (параметр 195) достаточно высоко. Остальные значения «СМАРТ» в норме, или близки к ней. Важно, что параметр 5 (Reallocated Sectors Count) – в норме. Это означает, что количество сбойных секторов невелико (11 в данном случае) и самому диску пока ничего не угрожает.

В случае, если параметр 5 отличается тревожными значениями, здоровье HDD под угрозой. На приведенном скриншоте графа Reallocated Sectors Count указывает, что ЖД близок к выходу из строя. В данном случае это – сбой системы (несоответствие нулевого значения RAW и критического показателя VAL указывает на это), и для приведения в норму требуется восстановление SMART жесткого диска. Но обычно такие сведения указывают, что HDD вот-вот сломается, и им уже нельзя нормально пользоваться.
Как сбросить или восстановить S.M.A.R.T. жесткого диска
Мы не можем рассказать подробно, как сбросить SMART жесткого диска. Это действие хоть и не является преступным (в отличие от той же смены IMEI смартфона), но может помочь недобросовестным торговцам продавать неисправные ЖД под видом новых. Но для пользователей, которым нужно знать, как восстановить SMART жесткого диска, чтобы вернуть его в строй после программного сбоя, разъясним ситуацию в общих чертах.
- Для сброса S.M.A.R.T. (ровно как и других сервисных задач) требуется подключение ЖД по интерфейсу COM. Для этого производители оснащают HDD специальным разъемом из 4 или 5 контактов. Он расположен рядом с гнездами для кабелей передачи данных и подачи питания. Новые компьютеры часто не имеют гнезда COM на задней панели, поэтому его функции выполняет специальная плата USB-COM.

Интерфейсные разъемы жесткого диска
 Что такое SMART HDD (жёсткого диска) и что нужно делать, если компьютер выдаёт надпись «smart status bad backup and replace».
Что такое SMART HDD (жёсткого диска) и что нужно делать, если компьютер выдаёт надпись «smart status bad backup and replace». Во всех современных накопителях последних лет абсолютно любого производителя присутствует система SMART (self-monitoring, analysis and reporting technology - технология предупреждения, анализа и самопроверки) жесткого диска, очень тесно связанная с функционированием накопителя.
Современные технологии SMART осуществляют: мониторинг различных параметров состояния диска, сканирование поверхности жесткого диска с дальнейшей автоматической заменой нечитаемых секторов и занесение их в error-log, т.н. список, где номера этих секторов хранятся в виде таблицы, периодическое повторное сканирование "ненадежных" секторов из error-log и, если система определяет, что данный сектор исправен - то исключает его из данного списка и он становится доступен на поверхности для пользовательской информации (но также помечается для дальнейшей перепроверки при следующем сканировании поверхности), либо, если сектор не прочитывается несколько раз подряд, не переписывается, то он отправляется в следующий дефект-лист,именуемый у разных производителей по-разному, но имеющий одинаковое предназначение - этот лист является как бы посредником между error-log таблицей и финальным G-листом, где дефект уже будет занесен в G-лист навсегда, станет отображаться в SMART, в строке current pending sectors/offline UNC sectors.
Из статуса current pending поврежденный сектор после очередной перепроверки на "живучесть", если не прошел чтение/запись, то окончательно отправляется в статус переназначенных и там уже остается. Диск в дальнейшей работе его уже не использует, не тестирует повторно на чтение/запись.
В строке reallocated sector count изменяется значение с N на N+1.
Если накопитель имеет уже серьёзные повреждения, то при загрузке компьютера может выводиться надпись: «smart status bad backup and replace». Это значит, что статус SMART жёсткого диска изменился из состояния GOOD в состояние BAD, на диске как минимум имеются BAD-блоки и состояние диска продолжает ухудшаться. Пользователю рекомендуется сохранить свои данные, если они ещё доступны для чтения и заменить жёсткий диск на новый.
SMART ВЫГЛЯДИТ ТАК:
Выводится в виде таблицы со следующими столбцами:
ID – ИДЕНТИФИКАЦИОННЫЙ НОМЕР ПАРАМЕТРА
Name – выводимое программой имя параметра
VAL – НОРМАЛИЗОВАННОЕ ЗНАЧЕНИЕ ПАРАМЕТРА (НОРМАЛИЗОВАННОЕ ЗНАЧИТ, В ДАННОМ СЛУЧАЕ, ЧТО ВНУТРЕННЕЕ (RAW) ЗНАЧЕНИЕ ПАРАМЕТРА ПРЕОБРАЗОВАНО ПО ОПРЕДЕЛЁННОМУ АЛГОРИТМУ ДЛЯ БОЛЕЕ УДОБНОГО И ПОНЯТНОГО ПРОСМОТРА ЗНАЧЕНИЯ. НАПРИМЕР, ВНУТРЕННИЙ ПАРАМЕТР ВСЕГДА УВЕЛИЧИВАЕТСЯ И МОЖЕТ ПРИНИМАТЬ ЗНАЧЕНИЕ В НЕСКОЛЬКО ТЫСЯЧ ЕДИНИЦ, А ВЫВОДИМОЕ ЗНАЧЕНИЕ ИЗМЕНЯЕТСЯ ОТ 100 ДО 0 И ОТОБРАЖЕНИЕ ВНУТРЕННЕГО ДИАПАЗОНА ИЗМЕНЕНИЯ ПАРАМЕТРА НА ВЫВОДИМЫЙ И ЕСТЬ, В ДАННОМ СЛУЧАЕ, НОРМАЛИЗАЦИЯ)
Wrst – худшее значение параметра за отрезок времени время
Thresh – пороговое значение, при достижении которого диск рекомендуется заменить
РАССМОТРИМ, КАКИЕ СУЩЕСТВУЮТ ПАРАМЕТРЫ В СИСТЕМЕ SMART. НАБОР ОТСЛЕЖИВАЕМЫХ ПАРАМЕТРОВ ЗАВИСИТ ОТ ПРОИЗВОДИТЕЛЯ ДИСКА И НЕ ВСЕ ИЗ ПЕРЕЧИСЛЕННЫХ БУДУТ ПРИСУТСТВОВАТЬ В ВАШЕМ СЛУЧАЕ.
Атрибуты SMART:
1 Raw read error rate - количество ошибок при считывании секторов с пластин.
2 Throughput Performance - общая производительность диска в относительных единицах.
3 Spin-up time - время раскрутки пластин от нуля до номинальной скорости вращения в миллисекундах
4 Number of spin-up times - количество циклов раскрутки/остановки пластин; отражает механический ресурс диска из-за ограниченного количества циклов запуска/останова.
5 Reallocated sector count - параметр отражает количество запасных секторов; когда диск находит ошибку чтения/записи/проверки, он переназначает плохой сектор на хороший из запасной зоны; нормализованное значение атрибута уменьшается по мере убывания запасных секторов; RAW-значение показывает количество преназначенных секторов, которое в норме должно быть ноль; на SSDRAW значение показывает количество неисправных блоков флеш-памяти.
6 Read Channel Margin - данный атрибут не используется в современных накопителях.
7 Seek error rate - количество ошибок позиционирования магнитных головок.
8 Seek Time Performance - средняя скорость позиционирования привода магнитных головок на указанный сектор; в SSDпараметр не используется
9 Power-on time - ожидаемое время жизни диска, основанное на времени, проведённом во включённом состоянии; нормализованное значение уменьшается со 100 до 0, связано с ресурсом диска; уменьшение этого параметра косвенно говорит о состоянии механики диска
10 Spin-up retries - количество попыток раскруток пластин при условии, что первая попытка была неудачная; считается с момента начала использования; на SSD не используется
12 Start/stop count - ожидаемое время жизни, основанное на количестве пусков/остановов пластин; каждый диск имеет ограниченное количество пусков/остановов, параметр уменьшается со 100 до 0; RAW значение показывает число включений/выключений
13 Soft Read Error Rate - у одних производителей этот параметр описывается, как указывающий на количество ошибок, не восстановленных ECC, а у других наоборот - восстановленных
100 Erase/Program Cycles - общее количество циклов чтения/записи для всей флеш-памяти за весь срок службы; SSD имеет ограничение на количество циклов чтения/записи, конкретное значение зависит от типа и производителя микросхем флеш-памяти
103 Translation Table Rebuild - количество событий перестроения внутренней таблицы адресов блоков при её повреждении и восстановлении; RAW значение показывает актуальное количество данных событий
170 Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
171 Program Fail Count - количество случаев неудавшейся записи блока флеш-памяти
172 Erase Fail Count - количество случаев неудавшейся операции стирания блока флеш-памяти
173 Wear Leveller Worst Case Erase Count - максимальное количество операций стирания, произведённых над блоком флеш-памяти
178 Used Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
180 Unused Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество неиспользованных резервных блоков
183 SATA Downshifts - показывает, как часто требовалось понизить скорость передачи по SATA (с 6Гб/c до 3Гб/с или 1.5Гб/с) для успешной передачи данных, при уменьшении значения атрибута следует заменить кабель
184 End-to-End error - количество ошибок, возникших в буфере диска; часть технологии HP SMART IV; может свидетельствовать о неисправности RAM-буффера диска
185 Head Stability - по атрибуту нет достоверной информации
186 Induced Op-Vibration Detection - по атрибуту нет достоверной информации
187 Reported UNC error - количество нескорректированных ошибок чтения
188 Command timeout - количество невыполненных диском команд из-за истечения времени ожидания
189 High Fly writes - количество ошибок записи, вызванных неправильной высотой полёта магнитной головки над поверхностью
190 Airflow temperature - температура воздуха внутри гермоблока HDD
191 G-Sense Errors - указывает сколько раз диск прерывал работу из-за ударов или вибрации
192 power-off retract cycles - количество неожиданных пропаданий питания, когда оно пропадало прежде, чем была получена команда на отключение диска; у hdd срок службы при неожиданном отключении значительно меньше, чем при нормальном; у ssd есть риск потери таблицы внутреннего состояния при неожиданном пропадании питания
193 load/unload cycles - количество перемещений бмг между зоной парковки и зоной данных; значение уменьшается от 100 до 0, raw содержит актуальное количество перемещений
194 hda temperature- температура блока магнитных головок
195 hardware ecc recovered- количество ошибок чтения, скорректированных кодом коррекции ошибок
196 reallocation events - общее количество переназначений секторов, включает и off-line сканирование и обычную работу
197 current pending sectors- количество нестабильных секторов, ожидающих перепроверки и, возможно, переназначения
198 offline scan unc sectors- количество плохих секторов, найденных диском при фоновом самосканировании; ухудшение этого параметра говорит о быстрой деградации поверхности
199 ultra dma crc errors- количество ошибок при передаче данных между диском и материнской платой; при ухудшении этого параметра стоит заменить кабель
200 write error rate - частота возникновения ошибок при записи
202 data address mark errors - количество ошибок при поиске запрошенного сектора
203 run out cancel - количество ошибок, вызванных неверной контрольной суммой при попытке коррекции ошибки
204 soft ecc corrections - количество ошибок, скорректированных кодом коррекции
206 flying height - девиация высоты полёта головки над поверхностью относительно оптимального значения; если головка слишком низко, она может повредить поверхность, если слишком высоко - увеличивается количество ошибок чтения
207 spin high current - величина тока, требуемая для раскрутки пластин
209 offline seek performance - производительность подсистемы поиска при выполнении off-line сканирования
220 disk shift - расстояние, на которое сместился пакет пластин относительно теоретического положения в результате механического повреждения или перегрева
227 torque amplification count - показывает сколько раз требовалось подавать увеличенный ток для раскрутки пластин
230 gmr head amplitude - амплитуда колебаний головок бмг
233 media wearout indicator - остаток ресурса памяти в ssd
240 head flying hours- время, проведённое головками в зоне пользовательских данных; значение уменьшается, обычно от 100 до 0
241 total lbas written - количество 512-и байтных блоков, записанных за всю жизнь устройства
242 total lbas read - количество 512-и байтных блоков, считанных за всю жизнь устройства
250 read error retry rate
Сложность интерпретации значений smart состоит в том, что ни на количество, ни на тип, ни на значения, ни на единицы измерения отслеживаемых параметров нет единого стандарта. поэтому реализация smart всегда зависит от конкретного производителя. нормализацию raw-значений в показатели атрибутов все делают по-своему, а результатом является статус проверки smart good или bad. поэтому достоверный вывод о состоянии диска можно сделать только проверив его поверхность какой-либо диагностической программой. но если нужно быстро оценить состояние диска и возможные проблемы, нужно обратить внимание на несколько основных, самых информативных атрибутов.
Наиболее важные аттрибуты smart:
5 reallocated sectors count - количество переназначенных секторов; рост значения этого атрибута свидетельствует об ухудшении состояния поверхности диска
Последовательность действий при наличии S.M.A.R.T. ошибки жесткого диска или SSD . Как исправить диск и восстановить утерянные данные. При загрузке компьютера или ноутбука появляется S.M.A.R.T. ошибка жесткого диска или SSD? После данной ошибки компьютер не работает как прежде, и вы опасаетесь о сохранности ваших данных? Не знаете как исправить ошибку?
Актуально для ОС : Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Что делать со SMART ошибкой?
Шаг 1: Прекратите использование сбойного HDD
Получение от системы сообщения о диагностике ошибки не означает, что диск уже вышел из строя. Но в случае наличия S.M.A.R.T. ошибки, нужно понимать, что диск уже в процессе выхода из строя. Полный отказ может наступить как в течении нескольких минут, так и через месяц или год. Но в любом случае, это означает, что вы больше не можете доверить свои данные такому диску.
Необходимо побеспокоится о сохранности ваших данных, создать резервную копию или перенести файлы на другой носитель информации. Одновременно с сохранностью ваших данных, необходимо предпринять действия по замене жесткого диска. Жесткий диск, на котором были определены S.M.A.R.T. ошибки нельзя использовать – даже если он полностью не выйдет из строя он может частично повредить ваши данные.
Конечно же, жесткий диск может выйти из строя и без предупреждений S.M.A.R.T. Но данная технология даёт вам преимущество предупреждая о скором выходе диска из строя.
Шаг 2: Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным. В таком случае можно использовать программу для восстановления данных жесткого диска – Hetman Partition Recovery .

Для этого:
- Загрузите программу , установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов . Нажав кнопку «Далее» , программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить» .
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой.
Шаг 3: Просканируйте диск на наличие «битых» секторов
Запустите проверку всех разделов жесткого диска и попробуйте исправить найденные ошибки.

Для этого, откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с SMART ошибкой. Выберите Свойства / Сервис / Проверить в разделе Проверка диска на наличия ошибок .
В результате сканирования обнаруженные на диске ошибки могут быть исправлены.
Шаг 4: Снизьте температуру диска
Иногда, причиной возникновения “S M A R T” ошибки может быть превышение максимально допустимой температуры работы диска. Такая ошибка может быть устранена путём улучшения вентиляции компьютера. Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась до нормального уровня, то SMART ошибка может больше не возникнуть.
Шаг 5:
Откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с ошибкой. Выберите Свойства / Сервис / Оптимизировать в разделе Оптимизация и дефрагментация диска .

Выберите диск, который необходимо оптимизировать и кликните Оптимизировать .
Примечание . В Windows 10 дефрагментацию и оптимизацию диска можно настроить таким образом, что она будет осуществляться автоматически.
Шаг 6: Приобретите новый жесткий диск
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени. То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
- Тип диска: HDD, SSD или SSHD . Каждому типу присущи свои плюсы и минусы, которые не имеют решающего значения для одних пользователей и очень важны для других. Основные из них – это скорость чтения и записи информации, объём и устойчивость к многократной перезаписи.
- Размер . Два основных форм-фактора дисков: 3,5 дюймов и 2,5 дюймов. Размер диска определяется в соответствии с установочным местом конкретного компьютера или ноутбука.
- Интерфейс
. Основные интерфейсы жестких дисков:
- SATA;
- IDE, ATAPI, ATA;
- SCSI;
- Внешний диск (USB, FireWire и.т.д.).
- Технические характеристики и производительность
:
- Вместимость;
- Скорость чтения и записи;
- Размер буфера памяти или cache;
- Время отклика;
- Отказоустойчивость.
- S.M.A.R.T . Наличие в диске данной технологи поможет определить возможные ошибки его работы и вовремя предупредить утерю данных.
- Комплектация . К данному пункту можно отнести возможное наличие кабелей интерфейса или питания, а также гарантии и сервиса.
Как сбросить SMART ошибку?
SMART ошибки можно легко сбросить в BIOS (или UEFI). Но разработчики всех операционных систем категорически не рекомендуют этого делать. Если же для вас не имеют ценности данные на жестком диске, то вывод SMART ошибок можно отключить.
Для этого необходимо сделать следующее:
- Перезагрузите компьютер , и с помощью нажатия указанной на загрузочном экране комбинации клавиш (у разных производителей они разные, обычно “F2” или “Del” ) перейдите в BIOS (или UEFI).
- Перейдите в: Аdvanced > SMART settings > SMART self test . Установите значение Disabled .
Примечание: место отключения функции указано ориентировочно, так как в зависимости от версии BIOS или UEFI, место расположения такой настройки может незначительно отличаться.
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман. Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска, можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства. Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
SMART ошибка для SSD диска
Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того, что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска. Например, “209 Remaining Drive Life”, “231 SSD life left” и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек, и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Новейшие накопители представлены интеллектуальными устройствами, способными анализировать свое состояние и своевременно информировать пользователя о неполадках. Для этого аппаратная часть включает оригинальную опцию S.M.A.R.T.

Назначение технологии SMART.
Львиная доля дисковых накопителей последних лет, функционирует с использованием технологии S.M.A.R.T. Сочетание расшифровывается как self-monitoring, analysis and reporting technology , что на русском звучит как механизм самоконтроля, анализа и отчетности. Ее первые разработки увидели свет в 1995 году и с тех пор технология постоянно совершенствуется.
С момента производства дисковый накопитель начинает считывать свое текущее состояние, определяя его с помощью специальных параметров или атрибутов. Они располагаются , доступ к которой имеет лишь встроенная программа. Просмотреть параметры позволяет отдельное ПО, чаще всего представленное утилитами от разработчиков конкретного жесткого диска. Через них в накопитель подаются вводные, после чего в журнале статистики появится информация о текущем состоянии диска.
В процессе эксплуатации накопителя, данные представленные в рамках параметров значения постоянно меняются. Параметры проходят путь с максимальных показателей, гарантирующих высокую производительность и эффективность до минимальных значений, связанных с высокой вероятностью выхода накопителя из строя.
Все представленные в рамках технологии S.M.A.R.T атрибуты имеет цифровой идентификатор. Как правило, он общий для накопителей различных версий, однако имеют место исключения. В данном отношении выделяется цифра 7, демонстрирующая ошибки в размещении головок на дисковую поверхность. Для цифровой идентификатор неактуален. В отличие от 7-ки, цифра 9, которая показывает общий период непосредственной работы накопителя за срок использования, ее поддерживают все типы дисков HDD и SSD.
Структура параметров, представлена несколькими полями, демонстрирующих состояние диска и его разделов в конкретный период. Предназначенные для считывания информации утилиты выводят на экран следующие параметры:
- ID – идентификационный номер
- name – название атрибута
- VAL – его текущее состояние
- Wrst – наихудший показатель за период эксплуатации
- Thresh – минимальный порог работоспособности
Показатели S.M.A.R.T
Существует несколько самых распространенных параметров. Они, за редким исключением, объединяют накопители большинства производителей, итак:
- Raw Read Error Rate – показатель числа ошибок считывания
- Throughput Performance – рабочая эффективность. Ее снижение указывает на необходимость замены
- Spin Up Time – период развертывания накопителя в рабочее состояние. Рост параметра демонстрирует изношенность или недостаток питания
- Start/Stop Count – показатель количества моментов развертывания диска, которое изначально ограничено его механической структурой
- Reallocated Sectors Count – атрибут отражает число запасных участков. Туда при неполадках перенаправляется информация. В идеале количество подобных действий должно составлять 0
- Read Channel Margin – канальный резерв. В наше время накопители обходятся без него
- Seek Error Rate – Отражение механического состояния накопителя, в числе прочего демонстрирует излишнюю вибрацию и перегрев
- Seek Time Performance – уровень оперативных возможностей, актуален лишь для дисков HDD
- Power-on Time – прогноз продолжительности функционирования накопителя исходя из периода эксплуатации. Максимальные показатели составляют 100 и с течением времени снижаются до 0
- Spin-Up Retry Count – количество дублирующих операций запуска. Их увеличение говорит об ошибках в механической структуре
Эти и другие атрибуты, идущие красным фоном, говорят о его критическом состоянии накопителя, что предполагает скорую поломку. Конкретного стандарта, объединяющего показатели параметров от различных производителей, не существует. В каждом случае нормальные значения индивидуальны, отражаясь в виде фона или статуса, где
- Good – хороший показатель
- Bad – плохой показатель.
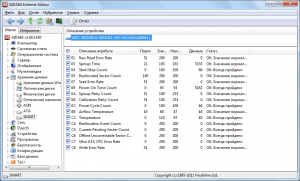

Наряду с уже упомянутыми атрибутами следует уделять внимание таким параметрам как:
- Recalibration Retries – число дублей при рекаблировке. Их повышение свидетельствует о неполадках механики
- End-to-End error – Недостатки обменных операций
- Reported UNC Errors – неполадки, чье устранение ведется с помощью аппаратных средств
- G-sense error rate – количество механических воздействий на диск. Фиксирует неаккуратную установку, столкновения
- Reallocation Event Count – общий показатель операций перенаправления информации. Фиксирует удачные и неудачные операции
- Current Pending Sector Count – количество потенциальных участков накопителя, подлежащих замене
- Uncorrectable Sector Count – количество неисправных секторов, неподлежащих восстановлению
- UltraDMA CRC Error Count – неполадки перенаправления данных между накопителем и ПК
Проверка S.M.A.R.T
Параметры S.M.A.R.T проверяются при помощи специальных утилит от производителей жестких дисков. Существуют и универсальные программы для тестирования и проверки дисков. Среди них выделяются udisks, smartctl, hddscan, CrystalDiskInfo, Victoria, используя которые пользователь сможет оценить состояние жесткого диска. В некоторых случаях, а именно при работе с контроллерами RAID, получить дисковые атрибуты практически невозможно.


Минимальный уровень диагностики поддерживается на уровне BIOS. Если включен режим диагностики S.M.A.R.T., то при наличии критических значений атрибутов BIOS не позволит загрузиться операционной системе.
Итак, тестируя состояние жесткого диска, прежде всего внимание, уделяется указанным параметрам S.M.A.R.T . Основное назначение технологии – прогнозирование выхода их строя жесткого диска. При опасном отклонении показателей от нормы, имеет смысл переносить важную информацию на другие носители.
И, самое главное, даже если в S.MA.R.T. никаких ошибок нет и все хорошо, это не является гарантией, что диск не сломается, так что .
Маленький рассказ об S.M.A.R.T. атрибутах, их важности и понимании. В статье пойдет речь об расшифровке всех smart атрибутов ATA дисков. В предыдущих статьях речь шла об и . Теперь хочу немного описать атрибуты обычных АТА дисков на примере Seagate Barracuda ES.2 (ST31000340NS). Так же определим самые важные атрибуты, на которые нужно обращать внимание при мониторинге дисков используя smartctl. Для начала, можно убедиться, что наш диск поддерживает смарт
Root@ s01:~# smartctl -i /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF INFORMATION SECTION === Model Family: Seagate Barracuda ES.2 Device Model: ST31000340NS Serial Number: 9QJ2ADVC … ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Fri Feb 21 16:18:35 2014 CET … SMART support is: Available - device has SMART capability. SMART support is: Enabled
Две последние строки свидетельствуют о том, что диск поддерживает smart и можно посмотреть значение всех его атрибутов и их интерпретация будет корректной(интерпретация RAW_VALUE) . В данном случаи тип интерфейса (устройства) не указывался явно (не было указанно атрибут «-d»), по этому smartctl автоматически определил тип устройства и сказал, что «SMART support is: Enabled». Но если используются, к примеру массивы дисков (RAID контроллер), то smartctl может сказать, что смарт не поддерживается:
Root@s06:~# smartctl -i /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net Vendor: SMC Product: SMC2108 Revision: 2.90 User Capacity: 2,996,997,980,160 bytes Logical block size: 512 bytes Logical Unit id: 0xSerial number: Device type: disk Local Time is: Fri Feb 21 17:32:27 2014 IST Device does not support SMART
Но на самом деле, нужно просто знать (или подбирать) какие дисковые массивы используются, и тогда можно получить желаемый результат явно указав тип устройства:
Root@s06:~# smartctl -d megaraid,14 -i /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net Vendor: SEAGATE Product: ST1000NM0001 Revision: 0002 User Capacity: 1,000,204,886,016 bytes Logical block size: 512 bytes Logical Unit id: 0x5000c50041080343 Serial number: Z1N0TV980000C2157TYR Device type: disk Transport protocol: SAS Local Time is: Fri Feb 21 17:34:45 2014 IST Device supports SMART and is Enabled Temperature Warning Enabled
Также может быть проблема в версии smartctl ибо не все жесткие диски добавляются в базу SMART сразу после выхода в мир нового HDD или RAID контроллера. Или же в BIOS отключено поддержку (нужно включить). Так же может быть проблема в прошивке (firmware) самого жесткого диска. Можете также стоит для начала попытаться включить SMART командой:
Root@s01:~# smartctl -s on /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF ENABLE/DISABLE COMMANDS SECTION === SMART Enabled.
Следующая, интересующая нас часть вывода покажет суммарный результат проверки статуса здоровья диска (Если не Passed – нужно проводить замену диска). Так же выводится дополнительные характеристики диска и предполагаемое время выполнения коротких и длинных тестов.
Root@s01:~# smartctl -Hc /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: (41) The self-test routine was interrupted by the host with a hard or soft reset. Total time to complete Offline data collection: (634) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: (1) minutes. Extended self-test routine recommended polling time: (226) minutes. Conveyance self-test routine recommended polling time: (2) minutes. SCT capabilities: (0x003d) SCT Status supported. SCT Error Recovery Control supported. SCT Feature Control supported. SCT Data Table supported.
В нашем случаи тип устройства определился автоматически и теперь можно вывести самое интересное — список атрибутов.
Root@s01:~# smartctl -A /dev/sda smartctl 5.41 2011-06-09 r3365 (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 068 059 044 Pre-fail Always - 130449727 3 Spin_Up_Time 0x0003 099 099 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 23 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 4 7 Seek_Error_Rate 0x000f 063 039 030 Pre-fail Always - 549998464474 9 Power_On_Hours 0x0032 052 052 000 Old_age Always - 42335 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 037 020 Old_age Always - 63 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 093 000 Old_age Always - 4295032870 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 076 049 045 Old_age Always - 24 (Min/Max 18/26) 194 Temperature_Celsius 0x0022 024 051 000 Old_age Always - 24 (0 17 0 0) 195 Hardware_ECC_Recovered 0x001a 041 021 000 Old_age Always - 130449727 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
Используя SMART можно предугадать с довольно большой вероятностью проблемы связанные с:
- Магнитными головками диска
- Физическими повреждениями диска
- Логическими ошибками
- Механическими проблемами (проблемы привода, системы позиционирования)
- Подачей питания (платы)
- Температурой
Расшифруем полученный вывод.

Каждый атрибут имеет группу значений:
- ID# — идентификационный номер атрибуты (детали ). Каждый атрибуты имеет свой уникальный ID, который должен быть одинаковым для всех фирм производителей дисков.
- ATTRIBUTE_NAME – название атрибута. Так как разные фирмы производители дисков могут называть атрибуты по своему (сокращать, синонимы), лучше всего ориентироваться по ID атрибута.
- FLAG (Status flag) – каждый атрибут имеет определенный флаг, назначенный фирмой разработчиком диска. В ОС с графическим интерфейсом значения этого флага предоставляется в виде набора буквенных обозначений – w,p,r,c,o,s (расшифровка ниже). И эти наборы предоставляются в виде шестнадцатеричного числа которые вы видели выше.
- W arranty: Указывает на жизненно важный атрибут диска и покрывается гарантией. Если этот флаг установлен и значение атрибута с этим флагом достигнет порогового (threshold) значения, в то время, когда диск еще на гарантии, то фирма должна будет заменить диск бесплатно.
- P erformance: Указывает на атрибут, который представляет показатель производительности диска – не критический.
- Error R ate: Атрибут с частотой ошибок.
- C ount of occurrences: Атрибут-счетчик происшествий.
- O nline test: Атрибут, который обновляет значения только через on-line тесты. Если не указан, то обновляется через off-line тесты.
- S elf preserving: Указывает на атрибут который может собирать и сохранять данные о диска, даже если S.M.A.R.T. отключен.
- Value – Текущее значение атрибута(оценка атрибута диска на основе Raw_value). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Это значение атрибута нужно сравнивать с пороговым (threshold) значением. Если это критический атрибут и значение ниже порогового — нужно проводить замену диска.
- Worst – Самое низкое значение атрибута за жизненный цикл диска. Значение может изменяться на протяжении жизни диска, и не должно быть ниже или равным пороговому значению (threshold).
- Thresh (Threshold) – Пороговое значения атрибута назначенное создателем диска. Значение не меняется за жизненный цикл диска. Если значение Value атрибута станет равным или меньше порогового – появиться уведомление в колонке WHEN_FAILED. И диск нужно заменить.
- Type – тип атрибута. Может быть критическим (pre-fail), который указывает на предстоящий отказ диска из-за ошибок или не критический, указывающий на достижение конца жизненного цикла диска.
- Raw_value – Объективное значения атрибута, которое показывается в десятичном формате (вычисляется firmware диска) и известных только производителю единицах (имеет связь с Value, Threshold и Worst значениями).
- WHEN_FAILED – Указывает на проблемы с атрибутом.
Атрибут диска примет значение failed, в случаи:
Value = f(Raw_value ) <= Threshold
- f(Raw_value) – функция вычисления деградации (уменьшения) значения параметра Value в зависимости от значения Raw_value.
Недостатки такого подхода к вычислению деградации диска:
- Для каждого производителя дисков и даже модели диска функция f(Raw_value) вычисляется по-разному.
- Оценка каждого атрибута подсчитывается независимо друг от друга – т.е. игнорируются связи между атрибутами.
Теперь хочу представить таблицу с перечисленными всех атрибутов. Те атрибуты, которые выделены розовым — относятся к атрибутам критическим. К тому же, указано тип параметра в зависимости от величины значения. Т.е. чем больше значение параметра, тем лучше состояние здоровья диска или наоборот.
Теперь приступим к атрибутам:
| #ID | HEX | Имя атрибута | Лучше если… | Описание |
|---|---|---|---|---|
| 01 | 01 | Raw Read Error Rate | Частота ошибок при чтении данных с жёсткого диска. Происхождение их обусловлено аппаратной частью винчестера. | |
| 02 | 02 | Throughput Performance | Общая производительность накопителя. Если значение атрибута уменьшается перманентно, то велика вероятность проблем с винчестером. | |
| 03 | 03 | Spin-Up Time | Время раскрутки шпинделя из состояния покоя (0 rpm) до рабочей скорости. В поле Raw_value содержится время в миллисекундах/секундах в зависимости от производителя | |
| 04 | 04 | Start/Stop Count | * | Полное число запусков, остановок шпинделя. Иногда в том числе количество включений режима энергосбережения. В поле raw value хранится общее количество запусков/остановок жёсткого диска. |
| 05 | 05 | Reallocated Sectors Count | Число операций переназначения секторов. При обнаружении повреждённого сектора на винчестере, информация из него помечается и переносится в специально отведённую зону, происходит утилизация bad блоков, с последующим консервированием этих мест на диске. Этот процесс называют remapping. Чем больше значение Reallocated Sectors Count, тем хуже состояние поверхности дисков - физический износ поверхности. Поле raw value содержит общее количество переназначенных секторов. | |
| 07 | 07 | Seek Error Rate | Частота ошибок при позиционировании блока магнитных головок. Чем больше значение, тем хуже состояние механики, или поверхности жёсткого диска. | |
| 08 | 08 | Seek Time Performance | Средняя производительность операции позиционирования. Если значение атрибута уменьшается, то велика вероятность проблем с механической частью. | |
| 09 | 09 | Power-On Hours (POH) | Время, проведённое устройством, во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ. | |
| 10 | 0A | Spin-Up Retry Count | Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. | |
| 11 | 0B | Recalibration Retries | Количество повторов рекалибровки в случае, если первая попытка была неудачной. | |
| 12 | 0C | Device Power Cycle Count | Число циклов включения-выключения винчестера. | |
| 13 | 0D | Soft Read Error Rate | Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. | |
| 187 | BB | Reported UNC Errors | Неустранимые аппаратные ошибки. | |
| 190 | BE | Airflow Temperature | Температура воздуха внутри корпуса жёсткого диска. Целое значение, либо значение по формуле 100 - Airflow Temperature | |
| 191 | BF | G-sense error rate | Количество ошибок, возникающих в результате ударов. | |
| 192 | C0 | Power-off retract count | Число циклов аварийных выключений. | |
| 193 | C1 | Load/Unload Cycle | Количество циклов перемещения блока головок в парковочную зону. | |
| 194 | C2 | HDA temperature | Показания встроенного термодатчика накопителя. | |
| 195 | C3 | Hardware ECC Recovered | Число коррекции ошибок аппаратной частью диска (ошибок чтения, ошибок позиционирования, ошибок передачи по внешнему интерфейсу). | |
| 196 | C4 | Reallocation Event Count | Число операций переназначения в резервную область, успешные и неудавшиеся попытки. | |
| 197 | C5 | Current Pending Sector Count | Число секторов- кандидатов на перенос в резервную зону. Помечены как не надёжные. При последующих корректных операциях атрибут может быть снят. | |
| 198 | C6 | Uncorrectable Sector Count | Число некорректируемых ошибок при обращении к сектору. | |
| 199 | C7 | UltraDMA CRC Error Count | Число ошибок при передаче данных по внешнему интерфейсу. | |
| 200 | C8 | Write Error Rate / Multi-Zone Error Rate | Общее количество ошибок при заполнения сектора информацией. Показатель качества накопителя. | |
| 201 | C9 | Soft read error rate | Частота появления «программных» ошибок при чтении данных с диска, а не аппаратной части HDD. | |
| 202 | Ca | Data Address Mark errors | Число ошибок адресно помеченной информации (Data Address Mark (DAM)).Если автоматически не корректируется - заменить устройство. | |
| 203 | CB | Run out cancel | Количество ошибок ECC данных, присоединяемые к передаваемому сигналу, позволяющие принимающей стороне определить факт сбоя или исправить несущественную ошибку. | |
| 204 | CC | Soft ECC correction | Количество ошибок ECC, скорректированных программным способом. | |
| 205 | CD | Thermal asperity rate (TAR) | Число ошибок в следствии температурных колебаний. | |
| 206 | CE | Flying height | * | Высота между головкой и поверхностью диска компьютера. |
| 209 | D1 | Offline seek performance | * | Drive’s seek performance during offline operations. |
| 220 | DC | Disk Shift | Дистанция смещения блока дисков относительно шпинделя. В основном возникает из-за удара или падения. | |
| 221 | DD | G-Sense Error Rate | Число ошибок, возникших из-за внешних нагрузок и ударов. Атрибут хранит показания встроенного crash датчика. | |
| 222 | DE | Loaded Hours | * | Время, проведённое блоком магнитных головок между выгрузкой из парковочной области в рабочую область диска и загрузкой блока обратно в парковочную область. |
| 223 | DF | Load/Unload Retry Count | * | Количество новых попыток выгрузок/загрузок блока магнитных головок винчестера в/из парковочной области после неудачной попытки. |
| 224 | E0 | Load Friction | Величина силы трения блока магнитных головок при его выгрузке из парковочной области. | |
| 225 | E1 | Load Cycle Count | Число циклов вход-выход в парковочную зону. | |
| 226 | E2 | Load ‘In’-time | * | Время, за которое привод выгружает магнитные головки из парковочной области на рабочую поверхность диска. |
| 227 | E3 | Torque Amplification Count | Количество попыток скомпенсировать вращающий момент. | |
| 228 | E4 | Power-Off Retract Cycle | Количество повторов автоматической парковки блока магнитных головок в результате выключения питания. | |
| 230 | E6 | GMR Head Amplitude | * | Амплитуда «дрожания» (расстояние повторяющегося перемещения блока магнитных головок). |
| 231 | E7 | Temperature | Температура жёсткого диска. | |
| 240 | F0 | Head flying hours | * | Время позиционирования головки. |
| 250 | FA | Read error retry rate | Число ошибок во время чтения жёсткого диска. |
Атрибуты дисков нужно смотреть в целом и самостоятельно прогнозировать замену, не только опираясь на smart атрибуты. Нужно дополнительно проводить тесты на бедблоки и запускать fscheck и smart тесты, о которых пойдет речь в следующих статьях.