データベースバックアップ用のユーティリティを理解しましょう。 SQLBase データベースのバックアップと復元の戦略
前回の資料でバックアップの問題についてはすでに触れましたが、 マイクロソフトのデータベース SQLサーバー、読者の反応は、理論的な部分をより深く研究した本格的な資料を作成する必要があることを示しました。 実際、これらの記事は実践的な手順に重点を置いて書かれており、バックアップを迅速に設定することができますが、特定の設定を選択する理由については説明されていません。 このギャップを修正してみましょう。
復旧モデル
バックアップを設定する前に、復旧モデルを選択する必要があります。 のために 最適な選択特定のモデルを実装する際のオーバーヘッド コストと比較して、回復要件とデータ損失の重大性を評価する必要があります。
ご存知のとおり、MS SQL データベースは、データベース自体とそのトランザクション ログの 2 つの部分で構成されています。 データベースには現時点でのユーザーとサービスのデータが含まれ、トランザクション ログには過去のすべてのデータベース変更履歴が含まれます。 一定期間、トランザクション ログがあれば、データベースの状態を任意の時点にロールバックできます。
運用環境で使用できる復旧モデルは 2 つあります。 シンプルで完全な。 が付いたモデルもあります 不完全なロギングただし、特定の時点でベースを復元する必要がない、大規模な大量作戦の期間中にフル モデルへの追加としてのみ推奨されます。
シンプルモデルデータベースのみのバックアップを提供します。したがって、バックアップが作成された時点のデータベースの状態のみを復元できます。最後のバックアップの作成から障害が発生するまでのすべての変更は失われます。 同じ時に 簡単な回路オーバーヘッドが低い: データベースのコピーを保存するだけでよく、トランザクション ログは自動的に切り捨てられ、サイズは増加しません。 また、回復プロセスは最も簡単で、時間もかかりません。
フルモデルデータベースを任意の時点に復元できますが、データベースのバックアップに加えて、復元が必要な期間全体のトランザクション ログのコピーを保存する必要があります。 で 活発な仕事データベースの場合、トランザクション ログのサイズ、つまりアーカイブのサイズが大きくなる可能性があります。 回復プロセスもはるかに複雑で時間がかかります。
復旧モデルを選択するときは、復旧のコストとバックアップの保存のコストを比較する必要があり、また、復旧を実行する担当者の可用性と資格も考慮する必要があります。 完全なモデルを使用した修復には、担当者に特定の資格と知識が必要ですが、単純なスキームの場合は指示に従うだけで十分です。
追加された情報の量が少ないデータベースの場合は、コピー頻度が高い単純なモデルを使用する方が収益性が高い場合があります。これにより、失われたデータを手動で入力することで迅速に回復し、作業を継続できます。 完全なモデルは主に、データ損失が許容できない場合や、最終的な回復にコストがかかる場合に使用する必要があります。
バックアップの種類
データベースの完全なコピー- その名前が示すように、データベースの内容と、バックアップが作成された時点のアクティブなトランザクション ログの一部 (つまり、現在および未完了のすべてのトランザクションに関する情報) を表します。 データベースをバックアップ作成時の状態に完全に復元できます。
デルタデータベースコピー- フルコピーには 1 つあります 重大な欠点、データベース内のすべての情報が含まれています。 バックアップを頻繁に作成する必要がある場合、ストレージの大部分が同じデータで占有されるため、ディスク領域の無駄な使用の問題が直ちに生じます。 この欠点を解消するには、前回のデータベース以降に変更された内容のみを含むデータベースの差分コピーを使用します。 フルコピー情報。
 差分コピーは前回のデータですのでご注意ください 満杯コピーする、つまり 後続の差分コピーには前のコピーのデータが含まれており (ただし、変更される可能性があります)、コピーのサイズは常に増加します。 復元するには、1 つの完全コピーと 1 つの差分コピー (通常は最後のコピー) で十分です。 差分コピーの数は、サイズの増加に基づいて選択する必要があります。差分コピーのサイズが完全コピーの半分のサイズに等しくなったら、新しい完全コピーを作成するのが合理的です。
差分コピーは前回のデータですのでご注意ください 満杯コピーする、つまり 後続の差分コピーには前のコピーのデータが含まれており (ただし、変更される可能性があります)、コピーのサイズは常に増加します。 復元するには、1 つの完全コピーと 1 つの差分コピー (通常は最後のコピー) で十分です。 差分コピーの数は、サイズの増加に基づいて選択する必要があります。差分コピーのサイズが完全コピーの半分のサイズに等しくなったら、新しい完全コピーを作成するのが合理的です。
トランザクションログのバックアップ- 完全復旧モデルにのみ適用され、前のコピーが作成された瞬間から始まるトランザクション ログのコピーが含まれます。

次の点に留意することが重要です。トランザクション ログのコピーはデータベースのコピーとはまったく関係がなく、以前のコピーの情報も含まれていないため、データベースを復元するには、必要な期間にわたってコピーの切れ目のないチェーンが必要です。データベースの状態をロールバックできるようになります。 この場合、最後にコピーが成功した時点がこの期間内である必要があります。
上の図を見てみましょう。ログ ファイルの最初のコピーが失われた場合、データベースの状態は完全コピーの時点でのみ復元できます。これは単純な復旧モデルと同様です。データベースのコピーの前のものから始まり、さらに続くログ コピーのチェーンが連続している場合、次の差分 (または完全) コピーの後のみ、データベースの状態をいつでも復元できます (図内) - 3 番目以降)。
トランザクションログ
回復と割り当てのプロセスを理解するため 他の種類バックアップの場合は、トランザクション ログの構造と動作を詳しく調べる必要があります。 取引は最低限のものです 論理演算、これは理にかなっていて、完全に満たすことしかできません。 このアプローチでは、操作の中間状態は受け入れられないため、あらゆる状況でデータの整合性と一貫性が保証されます。 トランザクション ログは、データベース内の変更を制御するために使用されます。
何らかの操作が実行されると、トランザクションの開始に関するレコードがトランザクション ログに追加され、各レコードには途切れることのないシーケンスから一意の番号 (LSN) が割り当てられ、データが変更されると、対応するエントリがログに作成されます。操作が完了すると、ログにトランザクションがクローズ(修正)されたことを示すマークが表示されます。
 各起動時に、システムはトランザクション ログを分析し、コミットされていないトランザクションをすべてロールバックすると同時に、ログに記録されたもののディスクに書き込まれなかった変更をロールバックします。 これにより、バックアップ電源システムがない場合でも、データの整合性を気にせずにキャッシュと遅延書き込みを使用できるようになります。
各起動時に、システムはトランザクション ログを分析し、コミットされていないトランザクションをすべてロールバックすると同時に、ログに記録されたもののディスクに書き込まれなかった変更をロールバックします。 これにより、バックアップ電源システムがない場合でも、データの整合性を気にせずにキャッシュと遅延書き込みを使用できるようになります。
アクティブなトランザクションが含まれ、データ回復に使用されるログの部分は、ログのアクティブ部分と呼ばれます。 これは、最小回復番号 (MinLSN) と呼ばれる番号で始まります。
最も単純なケースでは、MinLSN は最初の保留中のトランザクションのレコード番号です。 上の図を見ると、青色のトランザクションを開くと 321 に等しい MinLSN が取得されます。レコード 324 で修正された後、MinLSN 番号は 323 に変更されます。これはまだ緑色の番号に対応します。コミットされた、トランザクション。
実際には、すべてがもう少し複雑です。たとえば、クローズされた青色のトランザクションのデータがまだディスクにフラッシュされていない可能性があり、MinLSN を 323 に移動すると、この操作の回復が不可能になります。 このような状況を回避するために、コントロール ポイントの概念が導入されました。 次の状況が発生すると、チェックポイントが自動的に作成されます。
- CHECKPOINT ステートメントを明示的に実行する場合。 チェックポイントは、現在の接続データベースでトリガーされます。
- 一括ログ復旧モデルの対象となるデータベースに対して一括コピー操作を実行する場合など、データベースに対して最小限のログが記録される操作を実行する場合。
- ALTER DATABASE ステートメントを使用してデータベース ファイルを追加または削除するとき。
- SHUTDOWN ステートメントを使用して SQL Server のインスタンスを停止するとき、または SQL Server サービス (MSSQLSERVER) を停止するとき。 どちらの場合も、SQL Server インスタンス内のデータベースごとにチェックポイントが作成されます。
- SQL Server のインスタンスがデータベースの回復時間を短縮するために、各データベースに自動チェックポイントを定期的に作成する場合。
- データベースのバックアップを作成するとき。
- データベースのシャットダウンが必要なアクションを実行するとき。 例としては、AUTO_CLOSE パラメータを ON に設定し、データベースへのユーザーの最後の接続を閉じることや、データベースの再起動が必要なデータベース設定の変更などが挙げられます。
どのイベントが最初に発生したかに応じて、MinLSN はチェックポイント レコード番号または最も古い保留中のトランザクションの開始のいずれかに設定されます。
トランザクションログの切り捨て
トランザクション ログは、他のログと同様に、古いエントリを定期的に消去する必要があります。そうしないと、ログが増大して利用可能なスペースをすべて占有してしまいます。 データベースを積極的に操作している場合、トランザクション ログのサイズがデータベースのサイズを大幅に超える可能性があることを考慮すると、この問題は多くの管理者にとって重要です。
物理的には、トランザクション ログ ファイルは仮想ログのコンテナであり、ログが増大するにつれて順次いっぱいになります。 MinLSN エントリを含む論理ログはアクティブ ログの始まりであり、その前の論理ログは非アクティブであり、自動データベース回復には必要ありません。
 選択した場合 シンプルなモデルリカバリ後、論理ログのサイズが 70% に達したとき 物理ファイル起こっている 自動クリーニングログの非アクティブな部分、いわゆる。 切り捨て。 ただし、これは物理ログ ファイルを縮小するのではなく、論理ログを切り詰めるだけであり、この操作後に再利用できます。
選択した場合 シンプルなモデルリカバリ後、論理ログのサイズが 70% に達したとき 物理ファイル起こっている 自動クリーニングログの非アクティブな部分、いわゆる。 切り捨て。 ただし、これは物理ログ ファイルを縮小するのではなく、論理ログを切り詰めるだけであり、この操作後に再利用できます。
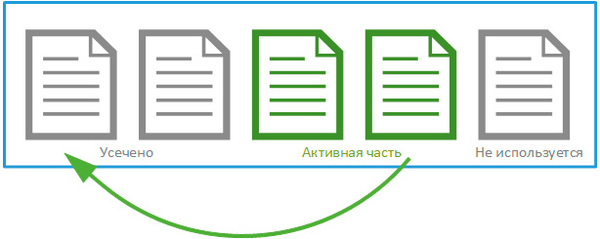
トランザクションの数が多く、物理ファイル サイズの 70% に達するまでに非アクティブな論理ログがなくなると、物理ファイル サイズが増加します。
 したがって、単純な復旧モデルを使用したトランザクション ログ ファイルは、ログのアクティブな部分全体が確実に含まれるまで、データベースの操作アクティビティに応じて増大します。 その後、その成長は止まります。
したがって、単純な復旧モデルを使用したトランザクション ログ ファイルは、ログのアクティブな部分全体が確実に含まれるまで、データベースの操作アクティビティに応じて増大します。 その後、その成長は止まります。
完全なモデルでは、ログの非アクティブな部分は完全に含まれるまで切り捨てることができません。 バックアップコピー。 トランザクション ログがバックアップされ、チェックポイントが作成されている場合、ログの切り捨てが発生します。
フル モデルでトランザクション ログ バックアップを誤って構成すると、ログ ファイルが制御不能に増大する可能性があり、これは経験の浅い管理者にとって問題になることがよくあります。 また、トランザクション ログを手動で切り詰めるというアドバイスもよく見かけます。 完全復旧モデルでは、これは断固として実行すべきではありません。これは、ログ コピーのチェーンの整合性に違反し、コピーが作成された時点でのみデータベースを復元できるためです。これは、単純なモデルに対応します。 。
この場合、記事の冒頭で述べたことを思い出してください。完全なモデルのコストが修復のコストを超える場合は、単純なモデルを優先する必要があります。
シンプルな復旧モデル
さて、受け取り後は 必要最低限の知識が得られたら、復旧モデルのより詳細な検討に進むことができます。 簡単なことから始めましょう。 障害が発生した時点で、完全コピーが 1 つと差分コピーが 2 つあったとします。
 バックアップを 1 日 1 回実行し、最後のコピーは 21 日から 22 日の夜に作成されました。 この障害は、22 日の夜、次のコピーが作成される前に発生します。 この場合、完全な差分コピーと最後の差分コピーを順番に復元する必要があり、最終営業日のデータは失われます。 何らかの理由で 21 日のコピーも破損していることが判明した場合は、前のコピーを復元して、さらに 1 日の作業を失うことができますが、同時に 20 日のコピーが破損しても作業が妨げられることはありません。対応するコピーが利用可能になった 21 日の夜にデータを正常に復元することはできませんでした。
バックアップを 1 日 1 回実行し、最後のコピーは 21 日から 22 日の夜に作成されました。 この障害は、22 日の夜、次のコピーが作成される前に発生します。 この場合、完全な差分コピーと最後の差分コピーを順番に復元する必要があり、最終営業日のデータは失われます。 何らかの理由で 21 日のコピーも破損していることが判明した場合は、前のコピーを復元して、さらに 1 日の作業を失うことができますが、同時に 20 日のコピーが破損しても作業が妨げられることはありません。対応するコピーが利用可能になった 21 日の夜にデータを正常に復元することはできませんでした。
完全復旧モデル
完全復旧モデルを使用した同様の状況を考えてみましょう。 また、完全 + 差分の原則を使用してバックアップを毎日作成し、トランザクション ログも 1 日に数回コピーします。
 この場合の回復プロセスはより複雑になります。 まず、ログの末尾 (赤色で表示) を手動でバックアップする必要があります。 最後のコピーが作成されてから事故が発生するまでのログの一部。
この場合の回復プロセスはより複雑になります。 まず、ログの末尾 (赤色で表示) を手動でバックアップする必要があります。 最後のコピーが作成されてから事故が発生するまでのログの一部。
これを行わないと、データベースを作成時の状態にしか復元できません。 最後のコピートランザクションログ。
この場合、前日のログ コピー ファイルが損傷しても、データベースの現在の状態を復元することはできますが、復元できるのは最後のコピーが作成された時点までに制限されます。 現在の日々。
次に、最後のバックアップ後に作成されたログの完全コピーと差分コピー、およびコピーのチェーンを順番に復元します。最後に復元するものは、ログの最後のフラグメントのコピーであり、データベースを正しく復元する機会が得られます。事故発生時、または事故に先立つ任意の事故時。
最後の差分コピーが破損した場合、単純なモデルの場合、さらに 1 日の作業が失われることになります。完全なモデルでは、最後から 2 番目のコピーを復元できます。その後、トランザクション チェーン全体を復元する必要があります。最後から 2 番目のコピーの瞬間から障害が発生するまでのログ コピー。 リカバリの深さは、ログの連続チェーンの深さにのみ依存します。
一方、トランザクション ログ コピーの 1 つ (たとえば、最後から 2 番目のコピー) が破損した場合、データを復元できるのは、最後のバックアップの時刻 + 無傷のログ コピー チェーンの期間までのみです。 たとえば、ログが 12 時、14 時、16 時に作成され、14 時に作成されたログが破損している場合、毎日のコピーがあれば、連続チェーンの終わりまでデータベースを復元できます。 12時まで。
タグ:
データベースの適切なバックアップは、IT インフラストラクチャの整合性にとって非常に重要です。 原則として、セキュリティ ポリシーの要件に準拠することが重要です。 DBMS プラグインに基づいて実装された Bacula Systems の高度なソリューションにより、Bacula Enterprise を使用するあらゆる企業がデータベースを迅速かつ確実にバックアップできるようになります。
シンプルさとスピードが重要な場合、適切なソリューション システム管理者厳しい時間制約の下で作業するには、Bacula Systems ツールを使用します。 データとメタデータ (ユーザー、権利、役割などに関するデータを含む) の安全性を管理するのに特別な知識は必要ありません。 同時に、ユーザーは次のことにアクセスできます。 十分な機会による カスタマイズ最も困難なプロフェッショナル環境で作業するために必要な柔軟性を提供するソフトウェア。
Oracleデータベースのバックアップ
データベースのバックアップと復元手順を簡素化します オラクルのデータ。 Oracle データベース管理者は、RMAN コマンドを使用してデータベースのバックアップをより簡単かつ便利に行うことができます。 Oracle 用プラグインは、スピードとシンプルさに加えて、その他の機能も大幅に最適化します。 重要な機能これには、任意の時点でのデータベースのリカバリや、バックアップおよびリカバリ中のオブジェクトのフィルタリングが含まれます。 これらすべての機能は、プラグインと Oracle RMAN リカバリ マネージャーとの緊密な統合を使用した「ダンプ」方法と事前定義ポイント リストア (PITR) 方法という 2 つのバックアップ方法のいずれかを使用して利用できます。
このプラグインは RMAN API sbt も使用するため、最初からファイルを書き込む必要がなくなります。 ローカルディスク。 「ダンプ」モードと RMAN モードの両方で、プラグインはバックアップ コピーを作成します。 意味のある情報これは、Oracle DB 管理のベスト プラクティスです。 通常、「ダンプ」方法と RMAN PITR 方法は、同じクラスターをバックアップするために一緒に使用されます。

Oracle の増分バックアップおよび差分バックアップの効率の向上
Bacula Systems の Oracle プラグインは、変更追跡を含む多くの RMAN コンポーネントを活用し、各データ ファイルから変更追跡ファイルにブロックを書き込むことでバックアップ パフォーマンスを向上させます。 変更追跡が有効な場合、RMANは変更追跡ファイルを使用して変更されたブロックを識別し、増分コピーを実行するため、データファイル内のすべてのブロックをスキャンする必要がなくなります。
Oracle データの回復
次の図に示すように、Oracle プラグインを使用すると、RMAN ユーティリティまたはダンプ方法を使用してデータベースを復元できます。

バックアップ用にサポートされている Oracle プラットフォームのバージョン
プラグインは 32 ビットと 64 ビットで利用できます Linuxのバージョン Oracle データベース バージョン 10.x、11.x と互換性があります。
PostgreSQL のバックアップと復元
これは、PostgreSQL データベース クラスターのバックアップと復元の手順を簡素化するために開発されました。 管理者は知る必要はありません 内部メソッド PostgreSQL バックアップまたは複雑なスクリプト手順。 このプラグインは、データベース構成、ユーザー定義、テーブルスペースなどの重要な情報を自動的にバックアップします。 PostgreSQL プラグインは、「ダンプ」と PITR という 2 つのバックアップ方法をサポートしています。
このプラグインは、Bacula Systems 独自の Late Data Inclusion (LDI) テクノロジーを使用して、バックアップが完了する直前までデータを効果的にキャプチャし、データ損失のリスクを最小限に抑えます。 これは、他のベンダーのソリューションと比較したこのプラグインの利点です。
PostgreSQLデータベースのホットバックアップ
PostgreSQL 用の Bacula Systems プラグインを使用すると、データベース管理者は WAL ファイル バックアップを使用して「ホット バックアップ」モードで PostgreSQL サーバーのバックアップを作成することもできます。
PostgreSQL のリカバリ

クラスターの内容

データベースの内容
バックアップ用にサポートされている PostgreSQL プラットフォームのバージョン
PostgreSQL データベースのバックアップは、32 ビット バージョンと 64 ビット バージョンの Linux で利用でき、PostgreSQL バージョン 8.4、9.0、9.1、9.2 をサポートします。 Bacula Enterprise ソフトウェア バージョン 6.0.6 以降で実行します。
MySQL データベースのバックアップと復元
これは、MySQL サーバーのバックアップおよびリカバリ手順を簡素化するために開発されました。 管理者は、MySQL の内部バックアップ方法や複雑なスクリプトを作成する手順を知る必要はありません。 このプラグインは構成可能で、データベース構成やユーザー定義などの重要な情報のバックアップを自動的に作成します。 MySQL プラグインは、「ダンプ」と「バイナリ」という 2 つのバックアップ方法をサポートしています。 
MySQLデータベースのバックアップ方法を選択可能
管理者は、より高速なバックアップとより大きなバックアップの作成のために、ダンプまたはバイナリ方法を選択できます。 MySQL プラグインは、PITR バックアップ機能を使用するときに MySQL ログ ファイルを処理します。
MySQLデータベースのデータ復旧

単一の MySQL データベースの復元

バックアップ用にサポートされている MySQL プラットフォームのバージョン
MySQL データベースのバックアップと復元は、32 ビット バージョンと 64 ビット バージョンの Linux で利用でき、MySQL バージョン 4.0.x、4.1.x、5.0.x、5.5.x、5.6.x をサポートします。
SQL Server データベースのバックアップ
VSS プラグインは、Bacula Systems ソフトウェアを使用して SQL Server データベースをバックアップする 2 つの方法のうちの 1 つです。 データベースのバックアップ SQLデータ VSS プラグイン経由のサーバーは、いくつかの特定のバックアップを行うように設計されています。 Windows コンポーネント、特に SQL Server データベース。 Bacula Enterprise VSS プラグインは、SQL Server データベースのバックアップの作成を大幅に簡素化します。
SQL Server データベースを迅速かつ簡単に復元する方法
VSS プラグインは、マスターまたは他のデータベース インスタンスを復元できます。 マスターを除くすべてのデータベースは、MS SQL の実行中に復元できます。 VSS プラグインは、MS SQL データベース移行プロセスと組み合わせて使用することもできます。

リカバリ中の SQL サーバー ツリー

移動されたデータベース
サポートされている SQL データベースのバックアップ バージョン
SQL データベースのバックアップは、Windows 2003 SP1 以降、Windows 2008 R1、および Windows 2008 R2 で実行されます。
SQL データベースのバックアップ - 高度な機能
は、複数の MS SQL データベースのバックアップ コピーを作成するための最新のソリューションであり、次のことが可能です。
- データベース ファイルとトランザクション ログ ファイルを保存する完全バックアップを実行して、ストレージ システムの障害を回避します。
- 差分バックアップでは、最後の完全バックアップの作成以降に変更されたデータのみが保存されます。 SQL Server 用の Bacula Enterprise プラグインには、必要に応じてバックアップを差分バックアップから完全バックアップにアップグレードするための統合オプションが含まれています。
- トランザクション ログをバックアップすることによる増分バックアップの作成。 対応機種に合わせた構成の場合、 この方法 PITRモードを使用できるようになります。
- マスター データベースをバックアップして、MS SQL 構成情報のバックアップ コピーを作成します。
強力な SQL データベース回復ツール
SQL 用 Bacula Enterprise プラグインは、PITR チェックポイント回復の使用など、いくつかの方法でデータを復元できます。 この場合、回復プロセスは次のシナリオを想定しています。
- ファイルをディスクにリカバリする
- 元のデータベースの復元
- 新しい名前でデータベースを復元する
- 新しい名前でデータベースを復元し、ファイルを移動する

「完全ログおよび部分ログ付き」データベース バックアップを作成するためのモデル
バックアップ用にサポートされている MS SQL プラットフォームのバージョン
MS SQL データベースのバックアップは、Windows 2003 R2、Windows 2008 R2、Windows 2012 および MS SQL Server 2005、2008、2014 で可能です。
Bacula Enterprise と専門家のサポートを利用したデータベースのバックアップに興味がありますか? ビデオをご覧ください。
の一つ 最も重要なタスクデータベース管理者が常に実行しなければならないのは、バックアップの実行です。 何か問題が発生した場合、サーバーをできるだけ早く再起動して実行するのが DBA の仕事です。 生産性の低下か何か それより悪い,データ損失はビジネスにとって非常に大きなコストをもたらす可能性があります。
最新のデータベースのバックアップが必要な場合は、次の構成を使用します。 RAIDディスク、データ保護を目的としたミラーの作成を提供しますが、これは万能薬ではありません。 RAID アレイは、データを損失から保護するための最初のステップにすぎません。 RAID アレイの構成に応じて、永久的なデータ損失が発生する前に、1 つ以上のハード ドライブに障害が発生する必要があります。 さらに、ホットスワップおよびホットスペア ディスクを使用すると、障害が発生した場合でもサーバーをシャットダウンせずに動作を継続できます。 ハードドライブ。 DBA について理解する必要がある重要な点は、 RAIDアレイハードドライブに障害が発生した場合でもデータを保護できます。 緊急事態(火災、洪水、盗難など)が発生した場合はどうなりますか? エラーによりデータベース ファイルが破損する ソフトウェアそれともハードウェアの故障でしょうか? 最後に、ユーザー (または DBA 自体) が将来突然必要になるデータを誤って削除した場合はどうなるでしょうか? このような場合、RAID 構成は役に立ちません。
最も重要なことは、管理者がいつでもサーバーを交換できることですが、このサーバー上のデータを回復するのは非常に難しく、場合によってはまったく不可能です。
いくつかの種類のデータベース バックアップを見てみましょう。
SQL Server は、フル、差分または差分、ログ コピーの 3 種類のバックアップをサポートします。 データベース全体を全体として処理する 3 つの主要なタイプのバックアップに加えて、単一のファイルまたはファイルのグループをコピーするために使用される追加のタイプのバックアップもいくつかあります。
完全バックアップ - すべてのデータベース エクステントの完全バックアップを作成します。 DBA が完全バックアップを使用してデータベースを復元する場合、必要なのは作成した最新のコピーのみです。 ただし、完全バックアップは最も遅いタイプのバックアップです。
差分バックアップ - 前回の完全バックアップ以降に変更されたエクステントのみをバックアップします。 DBA が差分バックアップを使用してデータベースを復元する場合、最新の完全バックアップと作成した最後の差分バックアップが必要になります。 差分バックアップははるかに高速ですが、完全バックアップと差分バックアップの両方が必要なため、回復時間が長くなります。
ログ バックアップ - 最後の完全バックアップまたは以前のトランザクション ログ コピーからトランザクション ログ バックアップを作成します。 DBA は、使用する復旧モデルに応じてトランザクション ログのバックアップを作成する必要があります (または作成しない場合もあります)。 完全バックアップとトランザクション ログ コピーを使用してデータベースを復元する場合、回復するには最新の完全バックアップとすべての (順番に) トランザクション ログ バックアップが必要になります。
バックアップは通常、データベースの実行中 (オンライン) に実行されることに注意してください。 このプロセスは一定期間にわたって実行されるため、「ファジー バックアップ」と呼ばれます。 データベース エクステントのバックアップ中に変更が発生した場合でも、コピー プロセスは当然続行されます。 整合性を維持するために、完全バックアップと差分バックアップでは、バックアップの開始から終了までの時間に対応するトランザクション ログ ファイルの部分がキャプチャされます。
SQL Server は、ハード ドライブにあるファイルにバックアップできます。 ネットワークドライブ、磁気テープ装置上。
データベースに対して行われたすべての変更は、必ずトランザクション ログに記録されます。 災害 (停電やブルー スクリーンなど) が発生した場合、トランザクション ログを使用してデータベースへの変更を回復できます。 さらに、チェックポイントはすべてのページを書き込むために使用されます。 ランダム・アクセス・メモリこれにより、データベースの復元に必要な時間が短縮されます。 それで、もし入っているなら、 コントロールポイントすべてのデータ ページはハード ドライブに書き込まれますが、なぜトランザクション情報を保存する必要があるのでしょうか? この質問に答えるには、復旧モデルについて話さなければなりません。
SQL Server 上で実行されている各データベースは、完全、一括ログ、シンプルの 3 つの復旧モデルのいずれかに従うことができます。
モデル 完全回復データ破損が発生した場合に最も多くのオプションを提供します。 すべてのトランザクションがログに記録され、完全回復モードが使用されている場合、トランザクションはバックアップされるまでログに保持されます。 データベースがバックアップされたら、 ディスクスペーストランザクション情報の保存に使用されていたが無料になり、新しいトランザクションの記録に使用できるようになります。 すべてのトランザクションがバックアップされるため、完全バックアップにより、 修復の可能性「」のデータベース 与えられたポイント「時間」の前に行われたトランザクションのみを使用します。 たとえば、完全バックアップを使用して復元を実行し、重要なデータが削除される前の特定の時点までのトランザクション ログのすべてのコピーを復元できます。
完全復旧モデルがデータベースに加えられたすべての変更を追跡し、すべてのトランザクションを任意の時点まで復旧できる場合、なぜ常にこのモデルを使用しないのかという疑問が生じます。 すべてのステートメントを完全にコミットする必要があるため、出力は非常に「重い」ログ ファイルになる可能性があります。 さらに、BULK INSERT などのコマンドは、行われたすべての変更をログに記録する必要があるため、サーバーの速度が低下します。
バッチ ログ モデル (bulk_logged) は完全復旧モデルとよく似ていますが、いくつかの追加点と利点があります。 完全復旧モデルと同様に、バッチ ログ モデルもすべての UPDATE、DELETE、INSERT ステートメントをキャプチャします。 ただし、特定のコマンドについては、このモデルは操作が行われたことのみを記録します。 これは、BULK INSERT、bcp、CREATE INDEX、SELECT INTO、WRITETEXT、UPDATETEXT などのコマンドに当てはまります。 バッチ ログ モデルは、すべてのトランザクションがバックアップされるまでログ スペースを再利用 (上書き) しないという点で、完全復旧モデルに似ています。
完全復旧モデルとは異なり、トランザクション ログにバッチ ステートメントが含まれている場合は、ポイントインタイム リカバリを実行することはできません。ログ全体の最後まで復旧する必要があります。 また、バッチ ログ モデルでは、ログ バックアップ プロセスで変更されたすべてのエクステントをコピーする必要があるため、データベース ログ バックアップのサイズが大きくなる可能性があります。
このモデルの利点は、多くのバッチ ステートメントを使用する場合にデータベースのトランザクション ログ ファイルを小さくできることです。 さらに、データベース内の変更自体ではなく、このステートメントの実行が行われたという事実のみが記録されるため、バッチ ステートメントの実行が速くなります。
シンプルな復旧モデル。 完全ログ モデルやバッチ ログ モデルとは異なり、単純復旧モデルはトランザクション ログ バックアップを使用しません。 このモデルでは、トランザクション ログは多くの場合、自動的に切り詰められます (切り詰めとは、ログから古いトランザクションを削除するプロセスです)。 モデル 簡単な回復完全バックアップと差分バックアップを使用できます。
データベース管理 ドキュメント管理
ご存知のとおり、サイトのすべての重要なデータ、その設定、記事、コメント、その他の情報はデータベースに保存されます。 この情報を失うと、プロジェクトに非常に悲惨な結果が生じる可能性があります。 したがって、mysql データベースのバックアップをタイムリーに作成することが重要です。 また、これらのコピーは、プロジェクトを別のサーバーに移動するときに非常に役立ちます。
この手順では、mysql または mariadb データベースをバックアップする方法と、コピーからデータベース内の情報を復元する方法について説明します。 ついでに設定方法も紹介します 自動作成一定期間後にコピーされます。
mysql バックアップに必要なのは、実行中のサーバーにアクセスすることだけです。 Linuxシステム、データベース サーバーがインストールされている場所、およびデータベース名とアクセス パラメータ。
mysqldump ユーティリティを使用して、データベースから SQL 形式で情報をエクスポートできます。 その構文は次のとおりです。
$ mysqldump options データベース名 [テーブル名] > file.sql
デフォルトでは、ユーティリティはすべてを標準出力に出力するため、このデータをファイルにリダイレクトする必要があります。これには、">" 演算子を使用します。 オプションは認証および操作パラメータを示し、データベースとテーブルの名前はエクスポートする必要があるデータを示します。 ここで、使用するオプションを簡単に見てみましょう。
- -A- すべてのデータベースからすべてのテーブルをコピーします。
- -私- 書き留める 追加情報コメントで;
- -c- INSERT ステートメントには列名を使用します。
- -a- 考えられるすべてのオプションを含めます CREATE文テーブル;
- -k- 無効化します 主キーコピーしている間。
- -e- INSERT ステートメントの複数行バージョンを使用します。
- -f- エラー後も続行します。
- -h- データベース サーバーが配置されているホスト名。デフォルトでは localhost。
- -n- データベースを作成するための手順を書かないでください。
- -t- テーブルを作成するための指示を書かないでください。
- -d- テーブルデータは書き留めず、その構造のみを書き留めます。
- -p- データベースのパスワード。
- -P- データベースサーバーポート。
- -Q- テーブル、データベース、フィールドの名前はすべて引用符で囲みます。
- -バツ- SQL の代わりに XML 構文を使用します。
- -u- データベースに接続するユーザー。
ほとんどの場合、ユーザー名、パスワード、データベース名を指定するだけで十分です。 次に、ユーティリティを使用した例を見てみましょう。 たとえば、最も 簡単なコマンドデータベースのエクスポート:
mysqldump -u ユーザー名 -p データベース名 > data-dump.sql
データベース ユーザーのパスワードを入力する必要があります。すべてのデータをファイルに送信したため、このコマンドは他に何も出力しませんが、次のコマンドを使用してバックアップ情報を表示できます。
head -n 5 データダンプ.sql

ただし、コピーの作成中にエラーが発生した場合は、画面に表示されるので、すぐにわかります。 もっと 難しい選択肢アクセスできる場合は、別のホストから mysql バックアップを実行します。
mysqldump -h ホスト -P ポート -u ユーザー名 -p データベース名 > data-dump.sql
mysql テーブルのコピーは、行の末尾にテーブル名を追加するだけで実行できます。
mysqldump -u ユーザー名 -p データベース名 テーブル名 > data-dump.sql
また、mysql データベースの自動バックアップを実行するには、すぐにパスワードを設定する必要がある場合があります。パスワードは、-p オプションの直後にスペースを入れずに指定します。
mysqldump -u ユーザー名 -ppassword データベース名 > data-dump.sql

時々手動でバックアップを作成することもできますが、他に重要な作業があるため、これは完全に便利というわけではありません。 したがって、cron スケジューラを使用してプロセスを自動化します。 2 つの方法があります。より単純な方法と、より複雑ですが正確な方法です。 毎日バックアップを作成する必要があるとします。その後、次の内容のスクリプトを /etc/cron.daily/ フォルダーに作成するだけです。
sudo vi /etc/cron.daily/mysql-backup
!/bin/bash
/usr/bin/mysqldump -u ユーザー名 -ppassword データベース名 > /backups/mysql-dump.sql

/backups/mysql-dump.sql フォルダーをバックアップ フォルダーに置き換える必要があります。 残っているのは、スクリプトに実行権限を与えることだけです。
chmod ugo+x /etc/cron.daily/mysql-backup
開いたファイルに次の行を追加し、変更を保存します。
30 2 * * * /usr/bin/mysqldump -u ユーザー名 -ppassword データベース名 > /backups/mysql-dump.sql
コマンドは毎日 2:30 に実行されます。夜間は通常サーバーの負荷が低いため、これは便利です。 ご存知のとおり、最初の数字は分、2 番目は時間、3 番目は日、次に週と月です。 アスタリスクは、このパラメータに値がないことを意味します。
バックアップからの復元
既存の SQL ファイルから mysql または mariadb バックアップを復元することも非常に簡単です。 使われていたので SQL 構文すべてのコマンドを単純に実行できます 標準クライアント mysql。
まず作成する必要があります 新しい基地データ。 これを行うには、スーパーユーザー権限で mysql サーバーにログインします。
mysql -u root -p
次に、たとえば new_database という名前で新しいデータベースを作成します。データベースがすでに存在する場合は、これを行う必要はありません。
mysql> データベースの作成 new_database;

mysql -u ユーザー -p データベース< data-dump.sql

エクスポートするには、標準出力データをファイルに送信しましたが、ここでは逆の操作が行われ、ファイルのデータがプログラムの標準入力に送信されます。 コマンドが正常に実行されても何も出力されません。すべてが正常に実行されたことを確認するには、データベースの内容を確認するだけです。
結論
これで、mysql データベースをコピーする方法と、コピーした情報を復元する方法がわかりました。 必要に応じてユーティリティをカスタマイズできるように、考えられるすべての mysqldump オプションを取り上げました。 MySQLデータベースのバックアップは非常に便利です 大事なポイント特定の状況では時間を大幅に節約できるため、必ずサーバーにセットアップしてください。
データベースのバックアップは、「ライブ」運用サーバー上で直接実行中のプロジェクトに対して常に構成する必要があります。
この状況は簡単に説明できます。 プロジェクトの最初の段階ではまだ空であり、コピーするものは何もありません。 急速な開発段階では、少数の開発者の頭は、「一昨日」という期限で重大なバグを修正するだけでなく、機能や装飾をねじ込むことに専念しています。 そして、プロジェクトが「出発」したときに初めて、システムの主な価値は蓄積されたデータベースであり、その失敗は大惨事になるという認識が生まれます。
このレビュー記事は、プロジェクトがすでにこの時点に達しているが、まだ餌を食べていない人向けです。
1. データベースファイルのコピー
MySQL データベースは、MySQL サーバーを一時的にオフにし、フォルダーからファイルをコピーするだけでコピーできます。 /var/lib/mysql/db/。 サーバーの電源がオフになっていない場合、明らかな理由により、データの損失や破損が発生する可能性があります。 ロードされたデータベースが大きい場合、この確率は 100% に近くなります。 さらに、データベースの「ダーティ」コピーを初めて使用する場合、MySQL サーバーはデータベース全体をチェックするプロセスを開始します。これには数時間かかる場合があります。ほとんどのライブ プロジェクトでは、データベース サーバーを長期間にわたって定期的にシャットダウンすることは受け入れられません。 この問題を解決するには、ファイル システムのスナップショットに基づくトリックが使用されます。 スナップショットは、特定の時点でのファイル システムの「写真」のようなもので、何もせずに撮影されたものです。 本物のコピーデータを(したがって迅速に)。 オブジェクトの遅延コピーは、多くの環境で同様に機能します。 現代語プログラミング。
アクションの一般的なスキームは次のとおりです。すべてのテーブルがロックされ、データベース ファイル キャッシュがリセットされ、ファイル システムのスナップショットが取得され、テーブルのロックが解除されます。 この後、ファイルはスナップショットから静かにコピーされ、その後スナップショットは破棄されます。 このようなプロセスの「ブロック」部分には約数秒かかりますが、これはすでに許容できる範囲です。 ペナルティとして、スナップショットが「生きている」間はしばらくパフォーマンスが低下します。 ファイル操作、これは主にデータベースへの書き込み操作の速度に影響します。
いくつかの ファイルシステムたとえば、ZFS は、スナップショットの取得をネイティブにサポートします。 ZFS を使用しないが、サーバー上に LVM ボリューム マネージャーがある場合は、スナップショット経由で MySQL データベースをコピーすることもできます。 最後に、*nix では R1Soft Hot Copy スナップショット ドライバーを使用できますが、このメソッドは openvz() コンテナーでは機能しません。
MyISAM データベースについては、公式の 無料のユーティリティ mysqlhotcopy : サーバーを停止せずに MyISAM データベース ファイルを「正しく」コピーします。 InnoDB にも同様のユーティリティがありますが、有料ですが、より多くの機能があります。
ファイルのコピーが最も重要です 早い方法データベース全体をあるサーバーから別のサーバーに転送します。
2. テキストファイル経由でコピーする
カウントするには バックアップデータ運用データベースからファイルをプルする必要はありません。 クエリを使用してデータを選択し、テキスト ファイルに保存できます。 これを行うには、SQL コマンド SELECT INTO OUTFILE とそのペア LOAD DATA INFILE を使用します。 アンロードは 1 行ずつ行われます (通常の SELECT と同様に、保存に必要な行のみを選択できます)。 テーブルの構造はどこにも指定されていないため、プログラマがこれに対処する必要があります。 データの整合性を確保するために、必要に応じてトランザクションに SELECT INTO OUTFILE コマンドを含めるように注意する必要もあります。 実際には、SELECT INTO OUTFILE は部分的なバックアップに使用されます。 大きなテーブル、他の方法ではコピーできません。ほとんどの場合、Igor Romanenko が作成した mysqldump ユーティリティの方がはるかに便利です。 mysqldump ユーティリティは、別のサーバー上のデータベースを完全に復元するために必要なすべての SQL コマンドを含むファイルを生成します。 個別のオプションを使用すると、このファイルをほぼすべての DBMS (MySQL だけでなく) と互換にすることができ、さらに、データを CSV および XML 形式でダウンロードすることもできます。 このような形式からデータを回復するには、mysqlimport と呼ばれるユーティリティがあります。
mysqldump コンソール ユーティリティ。 Web インターフェイス経由でバックアップを管理できるアドオンや類似品があります。たとえば、ウクライナのツール Sypex Dumper (代表的な zapimir は Habré にあります) です。
ユニバーサル バックアップ ユーティリティの欠点 テキストファイル- これは操作速度が比較的遅く、増分バックアップを作成できません。
3. 増分バックアップ
従来は、曜日ごとに 1 つずつ、2 週間前、1 か月前、および 4 か月前からのバックアップの合計 10 個のバックアップを保持することが推奨されています。これにより、データ破損が発生した場合に非常に詳細にロールバックできます。バックアップは、ライブ データベースと同じディスクや同じサーバーに保存しないでください。 火災やその他の災害に備えて、近くのデータセンターで数台レンタルするのが最善です。
これらの要件は、大規模なデータベースでは問題になる可能性があります。 100 ギガバイトのデータベースのバックアップを 100 メガビットのネットワーク経由でアップロードするには約 3 時間かかり、その間、チャネルが完全に詰まります。
増分バックアップは、次の場合にこの問題を部分的に解決できます。 完全バックアップこれは、たとえば日曜日にのみ行われ、他の日には過去 1 日間に追加または変更されたデータのみが書き込まれます。 難しいのは、まさにこの「その日のうちに変更されたデータ」をどのように特定するかです。
ここでは、変更された InnoDB エンジンを含む Percona XtraBackup システムが MySQL バイナリ ログを分析して抽出します。 必要な情報。 上記の有料の InnoDB Hot Backup もほぼ同じ機能を備えています。
バックアップに関する一般的な問題は、バックアップに常に遅れが生じることです。 メインサーバーに致命的な障害が発生した場合、時間内に何らかの「ロールバック」を行わなければシステムを復元できませんが、これはユーザーを非常に失望させることになります。 システム内の資金の流れが何らかの影響を受けた場合、そのような「リベート」には文字通りかなりの費用がかかる可能性があります。