スマートなHDD復号化。 S.M.A.R.T テクノロジーを使用したハードドライブの技術的状態の評価
専用自己診断ファームウェアS.M.A.R.T.を搭載。 (自己監視、分析、レポート技術)。 このテクノロジーにより、HDD の状態を監視し、その動作を分析し、故障を予測することができます。 「SMART」は 40 を超えるパラメータを監視し、それぞれの結果が特別なテーブルに入力されます。 S.M.A.R.T.統計の分析 脆弱性を検出し、ハードドライブの故障を予測できます。
この記事では、ハードドライブのSMARTを表示する方法、その読み取り値を解読する方法、およびどのパラメータに特別な注意を払う必要があるかを説明します。 情報は構造化された方法で表示されますが、そこからデータを抽出するには特別なソフトウェアが必要であることに注意してください。
S.M.A.R.T.の見方 ハードドライブ。 パラメータをデコードします。
「SMART」パラメータを確認するには、システムでこの機能が有効になっている必要があります。 これは、2010 年より前に製造されたコンピューターに当てはまります。 BIOS には HDD S.M.A.R.T オプションがあります。 「SMART」を完全に監視できる機能。 新しい PC で問題となるのは、「S.M.A.R.T. をどのように有効にするか」です。 ハードドライブ上にありますか? 関係ありません – すべてがデフォルトで有効になっています。
HDD ステータス パラメータを表示するには、HDD を操作するための特別なユーティリティ (Victoria、HD Tune、HDD Scan) または包括的な診断プログラム (Everest またはその「後継」Aida64) が必要です。 わかりやすい形式で表を表示できます。
Victoria を例としてパラメータを分析してみましょう。 画像からわかるように、ハード ドライブ (この場合、古い IDE インターフェイスを備えた 200 GB Seagate) はすべての「SMART」コマンドをサポートしているわけではなく、いくつかのパラメーターが修正されています。
テーブルのヘッダーには、パラメータ ID、その名前、VAL、Wrst、Tresh、Raw の値、および Health 評価列が表示されます。
- ID – 分析基準の一般リスト内のパラメータ番号。
- VAL は、抽象単位で表した現在の値 (通常は理想値のパーセンテージ) です。
- Wrst は、ハードドライブがこれまでに達成した最悪の値です。
- Tresh は VAL 値の条件付きしきい値であり、このしきい値に達すると、システムは HDD の差し迫った「死」を通知します。
- RAW – 数値形式での VAL パラメータの表現 (動作時間/障害/エラー/バグの数)。
Health パラメータを使用すると、コンピュータ ハードウェアの複雑さや英語に詳しくない人でも HDD の状態を評価できます。 彼はそれぞれに 1 から 5 ポイントの通常のスコアを割り当てます。
ハードドライブの状態を分析するときは、VAL (Tresh カラムとの比較) と RAW (客観的な評価) に注意を払う必要があります。 この例では、ハード ドライブで多くの読み取りエラーが発生しており (Seagate、Fujitsu、Samsung の場合、この列を見る必要はありません。すべてのエラーがここに記録されています)、動作時間が長い (パラメータ 9) ことは明らかです。 )。 この表は、ハードウェア エラー修正 (パラメータ 195) の数が非常に多いことを示しています。 残りの「SMART」値は正常またはそれに近い値です。 パラメーター 5 (再割り当てセクター数) が正常であることが重要です。 これは、不良セクタの数が少なく (この場合は 11)、ディスク自体はまだ危険にさらされていないことを意味します。

パラメータ 5 に警戒すべき値がある場合、HDD の健康状態が危険にさらされます。 上のスクリーンショットでは、再割り当てセクター数のグラフは、ハード ドライブが故障に近づいていることを示しています。 この場合、これはシステム障害です (ゼロの RAW 値とクリティカル VAL 値の間の不一致がこれを示しています)。通常の状態に戻すには、ハード ドライブの SMART 復元が必要です。 しかし、このような情報は通常、HDD が故障し、正常に使用できなくなっていることを示しています。
S.M.A.R.T.をリセットまたは復元する方法 ハードドライブ
SMART ハードドライブをリセットする方法について詳しく説明することはできません。 この行為は犯罪ではありませんが (スマートフォンの IMEI の変更とは異なります)、悪徳業者が欠陥のあるハードドライブを新しいハードドライブを装って販売するのに役立つ可能性があります。 ただし、ソフトウェア障害後に SMART ハードドライブを動作に戻すために復元方法を知る必要があるユーザーのために、一般的な用語で状況を説明します。
- S.M.A.R.T.をリセットするには (他のサービス タスクと同様に) COM インターフェイスを介したハード ドライブ接続が必要です。 これを行うために、メーカーは HDD に 4 ピンまたは 5 ピンの特別なコネクタを装備します。 データケーブルと電源用のソケットの隣にあります。 新しいコンピュータには背面パネルに COM ソケットがないことが多いため、その機能は特別な USB-COM カードによって実行されます。

ハードドライブインターフェースコネクタ
 SMART HDD (ハード ドライブ) とは何ですか。また、コンピュータに「スマート ステータスが不正なバックアップと交換」というメッセージが表示された場合はどうすればよいですか。
SMART HDD (ハード ドライブ) とは何ですか。また、コンピュータに「スマート ステータスが不正なバックアップと交換」というメッセージが表示された場合はどうすればよいですか。 近年のすべてのメーカーの最新ドライブには、ハード ドライブの SMART システム (自己監視、分析、およびレポート テクノロジ) が搭載されており、ドライブの動作と非常に密接に関係しています。
最新の SMART テクノロジは、ディスク状態のさまざまなパラメータを監視し、ハードディスクの表面をスキャンして読み取り不能なセクタを自動的に置き換え、それらをいわゆるエラー ログに記録します。 これらのセクターの数がテーブル形式で保存されているリスト、エラー ログから「信頼できない」セクターを定期的に再スキャンし、システムがこのセクターが正常であると判断した場合は、このセクターをこのリストから除外します。ユーザー情報として表面上で利用できます (ただし、次回の表面スキャン中にさらに再チェックするためにマークも付けられます)。または、セクタが連続して数回読み取られず、書き換えられない場合は、次のセクタに送信されます。欠陥リスト。メーカーによって名前は異なりますが、目的は同じです。このシートは、エラー ログ テーブルと最終的な G リストの間の仲介者のようなもので、欠陥はすでに G リストに登録されています。永久に保存され、SMART の現在の保留セクター/オフライン UNC セクターの行に表示されます。
現在の保留ステータスから、次回の生存可能性の再チェックの後、読み取り/書き込みが失敗した場合、損傷したセクタは最終的に再割り当てステータスに送られ、そこに残ります。 ディスクはそれ以降の操作では使用されなくなり、読み取り/書き込みの再テストは行われません。
再割り当てされたセクター数の行では、値が N から N+1 に変化します。
ドライブにすでに重大な損傷がある場合、コンピュータの起動時に「スマート ステータスが不良です。バックアップと交換を行ってください」というメッセージが表示されることがあります。 これは、ハード ドライブの SMART ステータスが GOOD 状態から BAD 状態に変化し、ディスクに少なくとも BAD ブロックがあり、ディスクの状態が悪化し続けていることを意味します。 データがまだ読み取れる場合は保存し、ハードドライブを新しいものと交換することをお勧めします。
スマートは次のようになります:
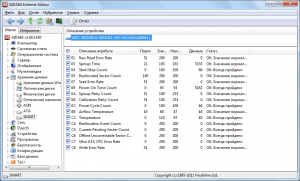
次の列を含むテーブルとして表示されます。
ID – パラメータ識別番号
名前 – プログラムによって表示されるパラメータ名
VAL – 正規化されたパラメータ値 (この場合、正規化とは、値をより便利で理解しやすくするために、内部 (生) パラメータ値が特定のアルゴリズムによって変換されることを意味します。たとえば、このパラメータは常に増加し、次の値を受け入れることができます。いくつか1000 単位の場合、表示値が 100 から 0 に変化し、内部パラメータの変更範囲が表示範囲に表示されます。この場合、正規化が行われます)
Wrst – 一定期間における最悪のパラメータ値
Thresh – しきい値に達すると、ディスクを交換することが推奨されます。
スマート システムにどのようなパラメータがあるかを考えてみましょう。 監視するパラメータのセットはディスクの製造元によって異なり、リストされているパラメータのすべてがあなたのケースに存在するわけではありません。
スマート属性:
1 Raw 読み取りエラー率 - プレートからセクターを読み取る際のエラーの数。
2 スループット パフォーマンス - 相対単位で表した全体的なディスク パフォーマンス。
3 スピンアップ時間 - プレートをゼロから公称回転速度までスピンする時間 (ミリ秒単位)
4 スピンアップ回数 - プレートのスピンアップ/停止サイクルの数。 始動/停止サイクルの数が限られているため、ドライブの機械的寿命を反映しています。
5 再割り当てセクター数 - このパラメーターはスペアセクターの数を反映します。 ディスクが読み取り/書き込み/検証エラーを検出すると、不良セクターをスペア領域から正常なセクターに再割り当てします。 スペアセクタが減少すると、属性の正規化された値が減少します。 RAW 値は割り当てられたセクターの数を示します。通常はゼロである必要があります。 SSDRAW の場合、値は不良フラッシュ メモリ ブロックの数を示します。
6 読み取りチャネル マージン - この属性は最新のドライブでは使用されません。
7 シークエラー率 - 磁気ヘッドの位置決めエラーの数。
8 シーク時間パフォーマンス - 指定されたセクターへの磁気ヘッド ドライブの位置決めの平均速度。 SSD ではこのパラメータは使用されません
9 電源投入時間 - 電源投入状態で費やした時間に基づく、ディスクの予想寿命。 正規化された値は、ディスク リソースに関連して 100 から 0 に減少します。 このパラメータの減少は、ディスク機構の状態を間接的に示します。
10 スピンアップ再試行 - 最初の試行が失敗した場合に、プレートを回転させようとする試行回数。 使用した瞬間からカウントされます。 SSDでは使用されません
12 開始/停止回数 - プレートの開始/停止回数に基づく予想寿命。 各ディスクの起動/停止の数には制限があり、パラメータは 100 から 0 に減ります。 RAW値はオン/オフスイッチの数を示します
13 ソフト読み取りエラー率 - 一部のメーカーは、このパラメータを ECC によって回復されなかったエラーの数を示すものとして説明していますが、他のメーカーは逆に回復されます。
100 消去/プログラム サイクル - 耐用年数全体にわたるフラッシュ メモリ全体の読み取り/書き込みサイクルの合計数。 SSD には読み取り/書き込みサイクル数に制限があり、具体的な値はフラッシュ メモリ チップの種類とメーカーによって異なります。
103 変換テーブルの再構築 - ブロック アドレスの内部テーブルが破損して復元されたときに再構築するイベントの数。 RAW 値は現在のイベント データ量を示します
170 予約ブロック数 - SSD 内の予約ブロック プールの状態を説明し、残りのブロックの割合を示します。 RAW 値は、使用されている予約ブロックの数を示す場合があります。
171 Program Fail Count - フラッシュ メモリ ブロックの書き込みに失敗した回数
172 Erase Fail Count - フラッシュ メモリ ブロックの消去操作が失敗した回数
173 Wear Leveler Worst Case Erase Count - フラッシュ メモリ ブロックで実行される消去操作の最大数
178 使用済み予約ブロック数 - SSD 内の予約ブロック プールの状態を説明し、残りのブロックの割合を示します。 RAW 値は、使用されている予約ブロックの数を示す場合があります。
180 未使用予約ブロック数 - SSD 内の予約ブロック プールの状態を説明し、残りのブロックの割合を示します。 RAW 値には、未使用の予約ブロックの数が表示される場合があります。
183 SATA Downshifts - データ転送を成功させるために SATA 転送速度を下げる必要があった頻度 (6Gb/s から 3Gb/s または 1.5Gb/s) を示し、属性値が低下した場合はケーブルを交換する必要があります。
184 エンドツーエンド エラー - ディスク バッファーで発生したエラーの数。 HP SMART IV テクノロジーの一部。 ディスク RAM バッファの障害を示している可能性があります
185 頭部の安定性 - この属性について信頼できる情報はありません
186 誘発された操作振動の検出 - この属性に関する信頼できる情報はありません
187 報告された UNC エラー - 未修正の読み取りエラーの数
188 コマンド タイムアウト - タイムアウトによりディスクで実行されなかったコマンドの数
189 High Fly writes - 磁気ヘッドの表面上の不正確な飛行高さによって引き起こされる書き込みエラーの数
190 エアフロー温度 - HDD 密閉ブロック内の空気温度
191 G-Sense エラー - 衝撃や振動によりドライブが動作を中断した回数を示します。
192 電源オフ格納サイクル - ディスクの電源を切るコマンドが受信される前に電源が失われた場合の予期しない電源停止の回数。 予期しないシャットダウン中の HDD の耐用年数は、通常のシャットダウン中よりも大幅に短くなります。 SSD には、予期しない電力損失が発生した場合に内部状態テーブルが失われるリスクがあります。
193 ロード/アンロード サイクル - パーキング ゾーンとデータ ゾーン間の BMG 移動の数。 値は 100 から 0 に減少します。生の値には現在の動きの数が含まれます。
194 hda 温度 - 磁気ヘッドユニットの温度
195 ハードウェア ecc が回復しました - エラー修正コードによって修正された読み取りエラーの数
196 個の再割り当てイベント - セクター再割り当ての合計数。オフライン スキャンと通常の作業の両方が含まれます。
現在保留中のセクターは 197 個 - 再チェックと再割り当てを待っている不安定なセクターの数
198 オフライン スキャン UNC セクター - バックグラウンドの自己スキャン中にディスクによって検出された不良セクターの数。 このパラメータの劣化は、表面の急速な劣化を示します。
199 ウルトラ dma crc エラー - ディスクとマザーボード間でデータを転送する際のエラーの数。 このパラメータが悪化した場合は、ケーブルを交換する価値があります
200 書き込みエラー率 - 書き込み時のエラーの頻度
202 データ アドレス マーク エラー - 要求されたセクターの検索時のエラー数
203 run out cancel - エラーを修正しようとしたときに不正なチェックサムが原因で発生したエラーの数
204 ソフト ECC 訂正 - 訂正コードによって訂正されたエラーの数
206 浮上高さ - 最適値に対するヘッドの表面からの浮上高さの偏差。 ヘッドが低すぎると表面を損傷する可能性があり、高すぎると読み取りエラーの数が増加します
207 スピン高電流 - プレートを回転させるのに必要な電流量
209 オフライン シーク パフォーマンス - オフライン スキャンを実行するときの検索サブシステムのパフォーマンス
220 ディスク シフト - 機械的損傷または過熱の結果、プレート パックが理論上の位置に対して移動した距離
227 トルク増幅カウント - プレートを回転させるために増加した電流を適用する必要があった回数を示します
230 gmr ヘッド振幅 - bmg ヘッドの振動振幅
233 メディア摩耗インジケーター - SSD の残りのメモリ リソース
240 ヘッド飛行時間 - ユーザー データ ゾーンでヘッドが費やした時間。 値は通常 100 から 0 に減少します。
合計 241 lba が書き込まれました - デバイスの寿命全体にわたって書き込まれた 512 バイトのブロックの数
合計 242 lba 読み取り - デバイスの全寿命にわたって読み取られた 512 バイト ブロックの数
250 読み取りエラーの再試行率
スマートバリューを解釈する際の難しさは、監視されるパラメータの数量、タイプ、値、または測定単位について単一の基準がないことです。 したがって、スマートの実装は常に特定のメーカーに依存します。 誰もが独自の方法で生の値を属性インジケーターに正規化し、その結果がスマートな良し悪しのチェックステータスになります。 したがって、ディスクの状態について信頼できる結論を下すには、診断プログラムでディスクの表面をチェックする必要があります。 ただし、ディスクの状態と考えられる問題を迅速に評価する必要がある場合は、いくつかの基本的で最も有益な属性に注意を払う必要があります。
スマートの最も重要な属性:
5 再割り当てセクター数 - 再割り当てされたセクターの数。 この属性の値が増加すると、ディスク表面の状態が悪化していることを示します。
S.M.A.R.T.が存在する場合の一連のアクション ハードドライブまたはSSDのエラー。 ディスクを修復し、失われたデータを回復する方法。 コンピューターまたはラップトップを起動すると、S.M.A.R.T が表示されます。 ハードドライブまたはSSDのエラー? このエラーの後、コンピュータは以前のように動作しなくなり、データの安全性が心配ですか? エラーを修正する方法がわかりませんか?
OS関連: Windows 10、Windows 8.1、Windows Server 2012、Windows 8、Windows Home Server 2011、Windows 7 (Seven)、Windows Small Business Server、Windows Server 2008、Windows Home Server、Windows Vista、Windows XP、Windows 2000、Windows NT。
SMART エラーが発生した場合はどうすればよいですか?
ステップ1:故障したHDDの使用を中止する
システムからエラー診断メッセージを受け取ったとしても、ディスクにすでに障害が発生しているわけではありません。 しかし、S.M.A.R.T.があれば。 エラーが発生した場合は、ディスクがすでに障害の進行中であることを理解する必要があります。 完全な障害は数分以内に発生する場合もあれば、1 か月または 1 年後に発生する場合もあります。 しかし、いずれにせよ、これは、そのようなドライブにデータを信頼できなくなったことを意味します。
データの安全性を心配し、バックアップ コピーを作成したり、ファイルを別の記憶媒体に転送したりする必要があります。 データの安全性を確保するとともに、ハードドライブを交換する措置を講じる必要があります。 S.M.A.R.T. がインストールされているハード ドライブ エラーを悪用することはできません。完全に失敗しなくても、データが部分的に損傷する可能性があります。
もちろん、S.M.A.R.T 警告が表示されずにハード ドライブに障害が発生する可能性があります。 ただし、このテクノロジーには、ディスクの差し迫った障害について警告できるという利点があります。
ステップ2:削除されたディスクデータを復元する
SMART エラーが発生した場合、必ずしもディスクからデータを復元する必要はありません。 ディスクはいつでも故障する可能性があるため、エラーが発生した場合は、重要なデータのコピーをすぐに作成することをお勧めします。 ただし、データをコピーできなくなるエラーが発生します。 この場合、プログラムを使用してハードドライブのデータを回復できます - ヘットマンパーティションの回復.

このために:
- プログラムをダウンロードし、インストールして実行します。
- デフォルトでは、ユーザーは使用するように求められます。 ファイル回復ウィザード。 ボタンを押すと "さらに遠く"を選択すると、プログラムはファイルを回復するドライブを選択するように求めます。
- 障害が発生したディスクをダブルクリックし、必要な分析タイプを選択します。 選ぶ 「完全分析」そしてディスクスキャンプロセスが完了するまで待ちます。
- スキャンプロセスが完了すると、リカバリファイルが提供されます。 必要なファイルを選択してボタンをクリックします "復元する".
- 提案されたファイルの保存方法のいずれかを選択します。 エラーが発生したディスクに回復されたファイルを保存しないでください。
ステップ 3:ディスクをスキャンして不良セクタを探します
すべてのハード ドライブ パーティションのスキャンを実行し、見つかったエラーを修正してみます。

これを行うには、フォルダーを開きます "このコンピュータ" SMART エラーが発生したディスクを右クリックします。 選択する プロパティ / サービス / チェック章内 ディスクのエラーをチェックしています.
スキャンの結果、ディスク上で見つかったエラーを修正できます。
ステップ 4:ディスク温度を下げる
「S M A R T」エラーの原因は、ディスクの最大許容動作温度を超えている場合があります。 このエラーは、コンピュータの換気を改善することで解決できます。 まず、コンピュータに十分な換気装置が備わっているかどうか、およびすべてのファンが適切に動作しているかどうかを確認します。
換気の問題を特定して修正し、その後ディスクの動作温度が通常のレベルまで低下した場合、SMART エラーは発生しなくなる可能性があります。
ステップ5:
フォルダーを開きます "このコンピュータ"エラーが発生したディスクを右クリックします。 選択する プロパティ / サービス / 最適化する章内 ディスクの最適化とデフラグ.

最適化したいドライブを選択し、クリックします。 最適化する.
注記。 Windows 10 では、ディスクのデフラグと最適化が自動的に行われるように構成できます。
ステップ6:新しいハードドライブを購入する
SMART ハードドライブのエラーが発生した場合、新しいドライブを購入するのは時間の問題です。 どのような種類のハード ドライブが必要かは、コンピュータの使用スタイルや使用目的によって異なります。
新しいドライブを購入する際に注意すべき点:
- ディスクの種類: HDD、SSD、または SSHD。 各タイプには独自の長所と短所があり、一部のユーザーにとっては重要ではありませんが、他のユーザーにとっては非常に重要です。 主なものは、情報の読み書きの速度、容量、繰り返しの上書きに対する耐性です。
- サイズ。 ドライブの主なフォームファクタには、3.5 インチと 2.5 インチの 2 つがあります。 ディスク サイズは、特定のコンピューターまたはラップトップの設置場所に応じて決定されます。
- インターフェース。 主要なハードドライブインターフェイス:
- SATA;
- IDE、ATAPI、ATA;
- SCSI;
- 外部ドライブ (USB、FireWire など)。
- 仕様と性能:
- 容量;
- 読み取りおよび書き込み速度。
- メモリバッファまたはキャッシュサイズ。
- 反応時間;
- フォールトトレランス。
- 頭いい。 ディスク上にこのテクノロジが存在すると、その動作中に発生する可能性のあるエラーを特定し、時間の経過とともにデータ損失を防ぐことができます。
- 装置。 この項目には、インターフェイスまたは電源ケーブルの入手可能性、保証およびサービスが含まれます。
SMARTエラーをリセットするにはどうすればよいですか?
SMART エラーは BIOS (または UEFI) で簡単にリセットできます。 しかし、すべてのオペレーティング システムの開発者は、これを行うことを断固として推奨しません。 ハード ドライブ上のデータが重要でない場合は、SMART エラー出力を無効にすることができます。
これを行うには、次のことを行う必要があります。
- コンピュータを再起動してください、ブート画面に示されているキーの組み合わせを押します(メーカーごとに異なりますが、通常は 「F2」または 「デル」) BIOS (または UEFI) に移動します。
- 次の場所に移動します: 高度な > スマート設定 > SMARTセルフテスト。 設定値 無効.
注記: BIOS または UEFI のバージョンによっては、この設定の場所が若干異なる場合があるため、機能を無効にする場所はおおよそで示されています。
HDD修理って価値あるの?
SMART エラーを排除する方法はいずれも自己欺瞞であることを理解することが重要です。 エラー発生の主な原因はハードドライブ機構の物理的な磨耗であることが多いため、エラーの原因を完全に排除することは不可能です。
故障したハード ドライブ コンポーネントを削除または交換するには、ハード ドライブを扱うための特別な研究室を備えたサービス センターに問い合わせることができます。
ただし、この場合の作業コストは、新しいデバイスのコストよりも高くなります。 したがって、すでに動作しなくなったディスクからデータを復元する必要がある場合にのみ修復を実行するのが合理的です。
SSDドライブのSMARTエラー
SSDドライブの動作に不満がなくても、徐々に性能が低下していきます。 その理由は、SSD ディスクのメモリ セルの書き換えサイクル数が限られているためです。 耐摩耗機能はこの影響を最小限に抑えますが、完全に排除するわけではありません。
SSD ドライブには、ドライブのメモリ セルの状態を示す独自の SMART 属性があります。 たとえば、「ドライブ残り寿命 209」、「SSD 残り寿命 231」などです。 これらのエラーは、セルのパフォーマンスが低下した場合に発生する可能性があり、これはセルに保存されている情報が損傷または消失する可能性があることを意味します。
障害が発生した場合、SSD ディスク セルは復元できず、交換することもできません。
最新のドライブは、その状態を分析し、問題についてユーザーに即座に通知できるインテリジェント デバイスに代表されます。 これを実現するために、ハードウェアにはオリジナルの S.M.A.R.T. オプションが含まれています。

SMART テクノロジーの目的。
近年のディスク ドライブの大部分は、S.M.A.R.T テクノロジーを使用して動作しています。 組み合わせは次のことを表します 自己監視、分析、レポート技術 、ロシア語では、自制心、分析、報告のメカニズムのように聞こえます。 最初の開発は 1995 年にリリースされ、それ以来、テクノロジーは絶えず改良されてきました。
製造の瞬間から、ディスク ドライブは現在の状態の読み取りを開始し、特別なパラメータまたは属性を使用して状態を定義します。 これらは配置されており、組み込みプログラムによってのみアクセスできます。 パラメータは別のソフトウェアを使用して表示できます。通常は、特定のハード ドライブの開発者が提供するユーティリティが使用されます。 これらを通じて入力がドライブに送信され、その後ディスクの現在の状態に関する情報が統計ログに表示されます。
ドライブの動作中、値のパラメータ内に表示されるデータは常に変化します。 パラメータは、高いパフォーマンスと効率を保証する最大値から、ドライブ障害の可能性が高い最小値まで変化します。
S.M.A.R.T テクノロジーのフレームワーク内で提示されるすべての属性にはデジタル識別子があります。 原則として、これは異なるバージョンのドライブに共通ですが、例外もあります。 この点で、数字の 7 が目立ち、ディスク表面上のヘッドの配置にエラーがあることを示しています。 デジタル識別子は関係ありません。 7 とは異なり、9 という数字は、使用期間全体にわたるドライブの直接操作の合計期間を示し、すべてのタイプの HDD および SSD ドライブでサポートされています。
パラメータの構造は、特定の期間におけるディスクとそのパーティションの状態を示すいくつかのフィールドで表されます。 情報を読み取るために設計されたユーティリティは、画面上に次のパラメータを表示します。
- ID – 識別番号
- 名前 – 属性名
- VAL – 現在の状態
- Wrd – 運用期間における最悪の指標
- Thresh – 最小パフォーマンスしきい値
S.M.A.R.T インジケーター
最も一般的なパラメータがいくつかあります。 まれな例外を除いて、ほとんどのメーカーのドライブが組み合わされているため、次のことが可能です。
- Raw Read Error Rate – 読み取りエラーの数を示す指標
- スループット パフォーマンス - 運用効率。 減少は交換の必要性を示します
- スピンアップ時間 – ドライブが動作状態になるまでの期間。 パラメータの増加は、消耗または栄養不足を示します
- 開始/停止回数 – ディスクが展開される回数の指標。最初は機械的構造によって制限されます。
- 再割り当てセクター数 – この属性はスペア セクターの数を反映します。 問題が発生した場合、情報はそこにリダイレクトされます。 理想的には、そのようなアクションの数は 0 である必要があります。
- チャネルマージンの読み取り – チャネル予約。 最近では、ドライブはそれなしでも問題ありません
- シーク エラー率 - 過度の振動や過熱など、ドライブの機械的状態を反映します。
- シーク時間パフォーマンス – HDD にのみ関連する運用能力のレベル
- 電源投入時間 – 動作期間に基づいたドライブの動作時間を予測します。 インジケーターの最大値は 100 で、時間の経過とともに 0 に減少します。
- スピンアップ再試行回数 – 重複した起動操作の数。 それらの増加は機械構造のエラーを示しています
これらの属性および背景が赤いその他の属性は、ドライブが重大な状態にあることを示し、障害が差し迫っていることを示します。 さまざまなメーカーのパラメーターインジケーターを組み合わせた特定の標準はありません。 いずれの場合も、正常な値は個人的なものであり、背景やステータスの形で反映されます。
- 良い - 良いインジケーター
- 「悪い」は悪い指標です。

すでに述べた属性に加えて、次のようなパラメータにも注意を払う必要があります。
- 再キャリブレーションの再試行 – 再キャリブレーション中のテイク数。 それらの増加は機械的な問題を示しています
- エンドツーエンドのエラー – 交換操作の欠点
- 報告された UNC エラー - ハードウェアを使用して解決できる問題
- G センス エラー率 – ディスクに対する機械的衝撃の数。 不正確な取り付けや衝突を検出
- 再割り当てイベント数 - 情報リダイレクト操作の一般的な指標。 成功した操作と失敗した操作を記録します
- 現在の保留中のセクター数 - 交換される可能性のあるドライブ セクションの数
- Uncorrectable Sector Count – 復元できない不良セクタの数
- UltraDMA CRC エラー数 - ドライブと PC 間のデータ リダイレクトに関する問題
S.M.A.R.Tチェック
S.M.A.R.T パラメータは、ハード ドライブ メーカーの特別なユーティリティを使用してチェックされます。 ディスクのテストとチェックを行うための汎用プログラムもあります。 その中には、udisks、smartctl、hddscan、CrystalDiskInfo、Victoria が含まれており、ユーザーはこれらを使用してハードドライブの状態を評価できます。 場合によっては、つまり RAID コントローラを使用している場合、ディスク属性を取得することはほとんど不可能です。


最小診断レベルは BIOS レベルでサポートされています。 S.M.A.R.T. 診断モードが有効になっている場合、重要な属性値がある場合、BIOS はオペレーティング システムの起動を許可しません。
したがって、ハードドライブの状態をテストするときは、まず指定された S.M.A.R.T パラメータに注意を払います。 このテクノロジーの主な目的は、ハードドライブの故障を予測することです。 指標に標準からの危険な逸脱がある場合、重要な情報を他のメディアに転送することは理にかなっています。
そして最も重要なことは、たとえS.MA.R.T. エラーはなく、すべて正常ですが、ディスクが壊れないという保証はありません。
S.M.A.R.T.についてのちょっとしたお話 属性、その重要性、理解。 この記事では、ATA ドライブのすべてのスマート属性の解読について説明します。 前回の記事では と についてお話しました。 ここで、Seagate Barracuda ES.2 (ST31000340NS) を例として、通常の ATA ドライブの特性について少し説明したいと思います。 また、smartctl を使用してディスクを監視するときに注意する必要がある最も重要な属性も決定します。 まず、ドライブがスマートをサポートしていることを確認できます。
Root@ s01:~# Smartctl -i /dev/sda Smartctl 5.41 2011-06-09 r3365 (ローカル ビルド) Copyright (C) 2002-11 by Bruce Allen、http://smartmontools.sourceforge.net === 開始情報セクション === モデル ファミリ: Seagate Barracuda ES.2 デバイス モデル: ST31000340NS シリアル番号: 9QJ2ADVC … ATA バージョン: 8 ATA 標準: ATA-8-ACS リビジョン 4 現地時間: Fri Feb 21 16:18:35 2014 CET … SMART サポートは次のとおりです: 利用可能 - デバイスは SMART 機能を備えています。 SMART サポート: 有効
最後の 2 行は、ディスクがスマートをサポートし、そのすべての属性の値を確認でき、それらの解釈が正しいことを示しています (RAW_VALUE 解釈)。 この場合、インターフェイス (デバイス) タイプが明示的に指定されていない (「-d」属性が指定されていない) ため、smartctl は自動的にデバイス タイプを検出し、「SMART support is: Enabled」と表示しました。 ただし、たとえば、ディスク アレイ (RAID コントローラ) が使用されている場合、smartctl は、smart がサポートされていないと伝えることができます。
Root@s06:~# Smartctl -i /dev/sda Smartctl 5.41 2011-06-09 r3365 (ローカル ビルド) 著作権 (C) 2002-11 by Bruce Allen、http://smartmontools.sourceforge.net ベンダー: SMC 製品: SMC2108 リビジョン: 2.90 ユーザー容量: 2,996,997,980,160 バイト 論理ブロック サイズ: 512 バイト 論理ユニット ID: 0xシリアル番号: デバイス タイプ: ディスク 現地時間: Fri Feb 21 17:32:27 2014 IST デバイスは SMART をサポートしていません
しかし実際には、どのディスク アレイが使用されているかを知る (または選択する) だけで、デバイス タイプを明示的に指定することで望ましい結果を得ることができます。
Root@s06:~# Smartctl -d megaraid,14 -i /dev/sda Smartctl 5.41 2011-06-09 r3365 (ローカル ビルド) Copyright (C) 2002-11 by Bruce Allen、http://smartmontools.sourceforge.netベンダー: SEAGATE 製品: ST1000NM0001 リビジョン: 0002 ユーザー容量: 1,000,204,886,016 バイト 論理ブロック サイズ: 512 バイト 論理ユニット ID: 0x5000c50041080343 シリアル番号: Z1N0TV980000C2157TYR デバイス タイプ: ディスク トランスポート プロトコル: SAS 現地時間: 2 月21 17:34:45 2014 ISTデバイスは SMART をサポートしており、有効になっています。 温度警告が有効です。
新しい HDD または RAID コントローラーが世にリリースされた直後に、すべてのハード ドライブが SMART データベースに追加されるわけではないため、smartctl バージョンにも問題が発生する可能性があります。 または、サポートが BIOS で無効になっています (有効にする必要があります)。 ハードディスク自体のファームウェアに問題がある可能性もあります。 次のコマンドを使用して SMART を有効にしてみることから始めることもできます。
Root@s01:~# Smartctl -s on /dev/sda Smartctl 5.41 2011-06-09 r3365 (ローカル ビルド) Copyright (C) 2002-11 by Bruce Allen、http://smartmontools.sourceforge.net === START有効化/無効化コマンド セクションの === SMART が有効。
出力の次の部分には、ディスクの健全性ステータスをチェックした結果が表示されます (合格しない場合は、ディスクを交換する必要があります)。 また、追加のディスク特性と、短期テストと長期テストの推定実行時間も表示されます。
Root@s01:~# Smartctl -Hc /dev/sda Smartctl 5.41 2011-06-09 r3365 (ローカル ビルド) Copyright (C) 2002-11 by Bruce Allen、http://smartmontools.sourceforge.net === 開始SMART データ セクションの読み取り === SMART 全体的な健全性自己評価テストの結果: 合格 一般的な SMART 値: オフライン データ収集ステータス: (0x82) オフライン データ収集アクティビティはエラーなしで完了しました。 自動オフライン データ収集: 有効。 セルフテスト実行ステータス: (41) セルフテスト ルーチンは、ハード リセットまたはソフト リセットによりホストによって中断されました。 オフライン データ収集を完了するまでの合計時間: (634) 秒。 オフライン データ収集機能: (0x7b) SMART はオフラインを即時に実行します。 自動オフライン データ収集のオン/オフのサポート。 新しいコマンド時にオフライン収集を一時停止します。 オフライン表面スキャンがサポートされています。 セルフテストがサポートされています。 搬送セルフテストをサポート。 選択的セルフテストがサポートされています。 SMART 機能: (0x0003) 省電力モードに入る前に SMART データを保存します。 SMART自動保存タイマーをサポートします。 エラー ログ機能: (0x01) エラー ログがサポートされています。 汎用ロギングがサポートされています。 短いセルフテスト ルーチンの推奨ポーリング時間: (1) 分。 延長セルフテスト ルーチンの推奨ポーリング時間: (226) 分。 搬送セルフテスト ルーチンの推奨ポーリング時間: (2) 分。 SCT 機能: (0x003d) SCT ステータスがサポートされています。 SCT エラー回復制御がサポートされています。 SCT 機能制御がサポートされています。 SCT データテーブルがサポートされています。
私たちの場合、デバイスのタイプは自動的に決定され、最も興味深いものである属性のリストを表示できるようになりました。
Root@s01:~# Smartctl -A /dev/sda Smartctl 5.41 2011-06-09 r3365 (ローカル ビルド) Copyright (C) 2002-11 by Bruce Allen、http://smartmontools.sourceforge.net === 開始SMART データ セクションの読み取り === SMART 属性のデータ構造リビジョン番号: 10 しきい値のあるベンダー固有の SMART 属性: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 068 059 044 Pre-fail Always 13 04497 27 3 スピンアップ時間 0x0003 099 099 000 プレフェイル 常に - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age 常に - 23 5 Reallocated_Sector_Ct 0x0033 100 100 036 プレフェイル 常に - 4 7 Seek_Error_Rate 0x000f 063 039 030 プレフェイル 常に - 54 9998464474 9 Power_On_Hours 0x0032 052 052 000 Old_age 常に- 42335 10 Spin_Retry_Count 0x0013 100 100 097 常にプリフェイル - 0 12 Power_Cycle_Count 0x0032 100 037 020 Old_age 常に - 63 184 End-to-End_Error 0x0032 100 100 099 Old_age 常に - 7 Reported_Uncorrect 0x0032 100 100 000 Old_age 常に - 0 188 Command_Timeout 0x0032 100 093 000 Old_age 常に - 4295032870 189 High_Fly_Writes 0x003a 100 100 000 Old_age 常に - 0 190 Airflow_Temperature_Cel 0x0022 076 049 045 Old_age 常に - 24 (最小/最大 18/ 26 19) 4 摂氏温度 0x0022 024 051 000 古い年齢 常に - 24 (0 17 0 0 ) 195 Hardware_ECC_Recovered 0x001a 041 021 000 Old_age 常に - 130449727 197 Current_Pending_Sector 0x0012 100 100 000 Old_age 常に - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old _age オフライン - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age 常に - 0
SMART を使用すると、以下に関連する問題をかなり高い確率で予測できます。
- 磁気ディスクヘッド
- ディスクへの物理的損傷
- 論理エラー
- 機械的問題 (ドライブの問題、位置決めシステム)
- 電源(ボード)
- 温度
結果の出力を解読してみましょう。

各属性には値のグループがあります。
- ID番号— 識別番号属性 (詳細)。 各属性には独自の一意の ID があり、これはすべてのディスク メーカーで同じである必要があります。
- 属性名- 属性名。 ディスクの製造元によって属性の呼び方 (略語、同義語) が異なる場合があるため、属性 ID でナビゲートすることをお勧めします。
- FLAG(ステータスフラグ)– 各属性には、ディスク開発者によって割り当てられた特定のフラグがあります。 グラフィカル インターフェイスを備えた OS では、このフラグの値は、w、p、r、c、o、s という一連の文字指定として提供されます (復号化は以下を参照)。 そして、これらのセットは、上で見たように 16 進数の形式で提供されます。
- W arranty: ドライブの重要な属性を示し、保証の対象となります。 このフラグが設定されており、ディスクの保証期間中にこのフラグを持つ属性の値がしきい値に達した場合、企業はディスクを無料で交換する必要があります。
- P erformance: ディスク パフォーマンス メトリックを表す属性を示します。重要ではありません。
- エラー R ate: エラー率を含む属性。
- C発生数: インシデントの属性数。
- ○ nline test: オンラインテストを通じてのみ値を更新する属性。 指定しない場合は、オフライン テストを通じて更新されます。
- S elf preserving: S.M.A.R.T. であってもディスクデータを収集および保存できる属性を示します。 無効。
- 価値– 現在の属性値 (Raw_value に基づくディスク属性推定)。 値が低い場合は、ディスクの急速な劣化または差し迫った障害の可能性を示します。 それらの。 属性の値が大きいほど良いことになります。 この属性値はしきい値と比較する必要があります。 これが重要な属性であり、値がしきい値を下回っている場合は、ディスクを交換する必要があります。
- 最悪– ドライブのライフサイクルにおける最小の属性値。 この値はディスクの寿命を通じて変化する可能性があり、しきい値 (threshold) 以下であってはなりません。
- しきい値 (しきい値)– ディスク作成者によって割り当てられた属性のしきい値。 この値は、ディスクのライフサイクル全体にわたって変化しません。 属性の値がしきい値以下になると、WHEN_FAILED 列に通知が表示されます。 そしてディスクを交換する必要があります。
- タイプ– 属性タイプ。 エラーによる差し迫ったディスク障害を示す事前失敗、またはディスクのライフサイクルの終わりに達したことを示す非クリティカルのいずれかになります。
- 生の値– 客観的な属性値。10 進数形式 (ディスク ファームウェアによって計算) およびメーカーのみが知っている単位で表示されます (値、しきい値、および最悪の値と関係があります)。
- WHEN_FAILED– 属性の問題を示します。
次の場合、ディスク属性は値「failed」を取得します。
価値= f( 生の値) <= しきい値
- f(生の値) – Raw_valueに応じてValueパラメータの値の劣化(減少)を計算する関数。
ディスク劣化を計算するこのアプローチの欠点は次のとおりです。
- 各ディスク メーカーおよびディスク モデルごとに、機能 f(生の値) 計算方法が異なります。
- 各属性のスコアは互いに独立して計算されます。 属性間の関係は無視されます。
ここで、すべての属性をリストした表を提示したいと思います。 ピンク色で強調表示されている属性は重要な属性です。 また、値に応じてパラメータの種類を示します。 それらの。 パラメータの値が大きいほど、ディスクの状態は良好になり、その逆も同様です。
次に、属性に移りましょう。
| #ID | 16進数 | 属性名 | できれば良いのですが... | 説明 |
|---|---|---|---|---|
| 01 | 01 | 生の読み取りエラー率 | ハードドライブからデータを読み取る際のエラーの頻度。 それらの起源はハードドライブのハードウェアによって決まります。 | |
| 02 | 02 | スループットパフォーマンス | 全体的なドライブ性能。 属性値が永続的に減少する場合は、ハードドライブに問題がある可能性が高くなります。 | |
| 03 | 03 | スピンアップ時間 | 静止 (0 rpm) から動作速度までのスピンドルの回転時間。 Raw_value フィールドには、メーカーに応じてミリ秒/秒単位の時間が含まれます。 | |
| 04 | 04 | スタート/ストップ回数 | * | 主軸の起動と停止の合計数。 省エネモードがオンになった回数も含まれる場合があります。 生の値フィールドには、ハードドライブの起動/停止の合計数が保存されます。 |
| 05 | 05 | 再割り当てされたセクター数 | セクター再マップ操作の数。 ハードドライブ上で損傷したセクタが検出されると、そのセクタからの情報がマークされて特別に指定された領域に転送され、不良ブロックが破棄されて、ディスク上のこれらの場所が保存されます。 このプロセスは再マッピングと呼ばれます。 再割り当てセクター数の値が高くなるほど、ディスク表面の状態、つまり表面の物理的な磨耗が悪化します。 raw 値フィールドには、再マップされたセクターの総数が含まれます。 | |
| 07 | 07 | シークエラー率 | 磁気ヘッドユニットの位置決めエラーの頻度。 値が高くなるほど、機構またはハードドライブの表面の状態が悪くなります。 | |
| 08 | 08 | 時間パフォーマンスを参照 | 位置決め動作の平均的なパフォーマンス。 属性値が低下した場合は、機械部分に問題が発生している可能性が高くなります。 | |
| 09 | 09 | 電源投入時間 (POH) | デバイスがオンの状態で費やした時間。 失敗間のパスポート時間がそのしきい値として選択されます。 | |
| 10 | 0A | スピンアップリトライ回数 | 最初の試行が失敗した場合に、ディスクを動作速度までスピンアップする試行を繰り返した回数。 | |
| 11 | 0B | 再キャリブレーションの再試行 | 最初の試行が失敗した場合の再キャリブレーションの繰り返し回数。 | |
| 12 | 0℃ | デバイスの電源サイクル数 | ハードドライブのオン/オフサイクルの数。 | |
| 13 | 0D | ソフト読み取りエラー率 | ソフトウェアが原因で修正できなかった読み取りエラーの数。 | |
| 187 | BB | 報告された UNC エラー | 致命的なハードウェア エラー。 | |
| 190 | なれ | エアフロー温度 | ハードドライブケース内の気温。 整数値または式を使用した値 100 - エアフロー温度 | |
| 191 | BF | G センスエラー率 | 衝撃によるエラーの数。 | |
| 192 | C0 | パワーオフリトラクト回数 | 緊急シャットダウンのサイクル数。 | |
| 193 | C1 | ロード/アンロードサイクル | ヘッドブロックをパーキングゾーンに移動するサイクル数。 | |
| 194 | C2 | HDA温度 | ドライブの内蔵熱センサーからの読み取り値。 | |
| 195 | C3 | ハードウェアECCが回復しました | ディスク ハードウェアによって訂正されたエラーの数 (読み取りエラー、位置決めエラー、外部インターフェイスを介した送信エラー)。 | |
| 196 | C4 | 再割り当てイベント数 | スペア領域への再マップの数、成功および失敗。 | |
| 197 | C5 | 現在の保留中のセクター数 | リザーブゾーンへの転送候補セクターの数。 信頼できないとしてマークされています。 その後の正しい操作中に、属性を削除できます。 | |
| 198 | C6 | 修正不可能なセクタ数 | セクターにアクセスする際の訂正不可能なエラーの数。 | |
| 199 | C7 | UltraDMA CRC エラー数 | 外部インターフェイス経由でデータを転送する際のエラーの数。 | |
| 200 | C8 | 書き込みエラー率 /マルチゾーンエラー率 | セクターに情報を入力する際のエラーの合計数。 ドライブ品質インジケーター。 | |
| 201 | C9 | ソフトリードエラー率 | HDD ハードウェアではなく、ディスクからデータを読み取る際の「ソフトウェア」エラーの発生頻度。 | |
| 202 | Ca | データアドレスマークエラー | アドレスマーク情報(データアドレスマーク(DAM))のエラー数が自動修正されない場合は、デバイスを交換してください。 | |
| 203 | CB | 品切れキャンセル | 受信側で障害が発生したかどうかを判断したり、軽微なエラーを修正したりできるようにするために、送信信号に付加される ECC データ エラーの数。 | |
| 204 | CC | ソフトECC訂正 | ソフトウェアによって訂正された ECC エラーの数。 | |
| 205 | CD | サーマルアスペリティ率(TAR) | 温度変動によるエラーの数。 | |
| 206 | CE | 飛行高さ | * | ヘッドとコンピューターのディスク表面の間の高さ。 |
| 209 | D1 | オフラインシークパフォーマンス | * | オフライン操作中のドライブのシーク パフォーマンス。 |
| 220 | 直流 | ディスクシフト | スピンドルに対するディスクブロックの変位距離。 主に衝撃や落下によって引き起こされます。 | |
| 221 | DD | G センスエラー率 | 外部の負荷や衝撃によって発生したエラーの数。 この属性には、内蔵衝突センサーの測定値が保存されます。 | |
| 222 | DE | ロード時間 | * | 磁気ヘッドのブロックがパーキング エリアからディスクの作業エリアにアンロードされてから、ブロックがパーキング エリアに戻されるまでに費やされる時間。 |
| 223 | DF | ロード/アンロードの再試行回数 | * | 失敗した後にハードドライブの磁気ヘッドのブロックをパーキングエリアにアンロード/パーキングエリアからアンロード/ロードしようとする新たな試行の数。 |
| 224 | E0 | 負荷摩擦 | 磁気ヘッドブロックをパーキングエリアから降ろすときの摩擦力の大きさ。 | |
| 225 | E1 | ロードサイクル数 | 駐車ゾーンへの出入りのサイクル数。 | |
| 226 | E2 | 「インタイム」でロード | * | ドライブが磁気ヘッドをパーキングエリアからディスクの作業面にアンロードする時間。 |
| 227 | E3 | トルク増幅回数 | トルクを補正しようとする試行回数。 | |
| 228 | E4 | パワーオフリトラクトサイクル | 電源OFFによる磁気ヘッドユニットのオートパーキングの繰り返し回数。 | |
| 230 | E6 | GMR ヘッド振幅 | * | ジッター振幅(磁気ヘッドユニットが繰り返し移動する距離)。 |
| 231 | E7 | 温度 | ハードドライブの温度。 | |
| 240 | F0 | 飛行時間 | * | ヘッドの位置決め時間。 |
| 250 | FA | 読み取りエラーの再試行率 | ハードディスクの読み取り中のエラーの数。 |
スマート属性だけに依存するのではなく、ディスクの属性を全体として見て、独立して交換を予測する必要があります。 さらにベッドブロックのテストを実施し、fscheck テストとスマート テストを実行する必要があります。これについては次の記事で説明します。