Сегментация изображения. «Мягкая» семантическая сегментация изображений
Рассматриваются математические методы сегментации изображений стандарта Dicom. Разрабатываются математические методы сегментации изображений стандарта Dicom для задач распознавания медицинских изображений. Диагностика заболеваний зависит от квалификации исследователя и требует от него визуально проводить сегментацию, а математические методы по обработке растровых изображений являются инструментом для данной диагностики. Обработка полученных аппаратным обеспечением медицинских изображений без предварительной обработки графических данных в большинстве случаев дает неверные результаты. Выполнялись процедуры выделения контуров объектов методом Canny и дополнительными алгоритмами обработки растровых изображений. Результаты исследований позволяют вычислить необходимые для дальнейшего лечения пациента морфометрические, геометрические и гистограммные свойства образований в организме человека и обеспечить эффективное медицинское лечение. Разработанные принципы компьютерного автоматизированного анализа медицинских изображений эффективно используются для оперативных задач медицинской диагностики специализированного онкологического учреждения, так и в учебных целях.
распознавание образов
сегментация объектов интереса
медицинские изображения
1. Власов А.В., Цапко И.В. Модификация алгоритма Канни применительно к обработке рентгенографических изображений // Вестник науки Сибири. – 2013. – № 4(10). – С. 120–127.
2. Гонзалес Р., Вудс Р. Цифровая обработка изображений. – М.: Техносфера, 2006. – С. 1072.
3. Кулябичев Ю.П., Пивторацкая С.В. Структурный подход к выбору признаков в системах распознавания образов // Естественные и технические науки. – 2011. – № 4. – С. 420–423.
4. Никитин О.Р., Пасечник А.С. Оконтуривание и сегментация в задачах автоматизированной диагностики патологий // Методы и устройства передачи и обработки информации. – 2009. – № 11. – С. 300–309.
5. Canny J. A Computational approach to edge detection // IEEE Transactions on pattern analysis and machine intelligence. – 1986. – № 6. – P.679–698.
6. DICOM – Mode of access: http://iachel.ru/ zob23tai-staihroe/ DICOM
7. Doronicheva A.V., Sokolov A.A., Savin S.Z. Using Sobel operator for automatic edge detection in medical images // Journal of Mathematics and System Science. – 2014. – Vol. 4, № 4 – P. 257–260.
8. Jähne B., Scharr H., Körkel S. Principles of filter design // Handbook of Computer Vision and Applications. Academic Press. – 1999. – 584 p.
Одним из приоритетных направлений развития медицины в России является переход на собственные инновационные технологии электронной регистрации, хранения, обработки и анализа медицинских изображений органов и тканей пациентов. Это вызвано увеличением объемов информации, представленной в форме изображений, при диагностике социально значимых заболеваний, прежде всего онкологических, лечение которых в большинстве случаев имеет результат только на ранних стадиях.
При проведении диагностики изображений стандарта DICOM определяется патологическая область, при подтверждении ее патологического характера решается задача классификации: отнесение к какому-либо из известных видов или выявление нового класса. Очевидная сложность - дефекты получаемого изображения, обусловленные как физическими ограничениями оборудования, так и допустимыми пределами нагрузки на организм человека. В результате именно на программные средства ложится задача дополнительной обработки изображений с целью повысить их диагностическую ценность для врача, представить в более удобном виде, выделить главное из больших объемов получаемых данных.
Цель исследования . Разрабатываются математические методы сегментации изображений стандарта Dicom для задач распознавания медицинских изображений. Диагностика заболеваний зависит от квалификации исследователя и требует от него визуально проводить сегментацию, а математические методы по обработке растровых изображений являются инструментом для данной диагностики. Обработка полученных аппаратным обеспечением медицинских изображений без предварительной обработки графических данных в большинстве случаев дает неверные результаты. Это связано с тем, что изначально изображения получены неудовлетворительного качества.
Материал и методы исследования
В качестве материала исследований используются компьютерные томограммы пациентов специализированного клинического учреждения. Прежде чем анализировать реальные графические данные, необходимо изображение подготовить или произвести предобработку. Этот этап решает задачу улучшения визуального качества медицинских изображений. Полезно разделить весь процесс обработки изображений на две большие категории: методы, в которых как входными данными, так и выходными являются изображения; методы, где входные данные - изображения, а в результате работы выходными данными выступают признаки и атрибуты, выявленные на базе входных данных. Этот алгоритм не предполагает, что к изображению используется каждый из вышеприведенных процессов. Регистрация данных - первый из процессов, отраженный на рис. 1.
Рис. 1. Основные стадии цифровой обработки графических данных
Регистрация может быть достаточно простой, как в примере, когда исходное изображение является цифровым. Обычно этап регистрации изображения предполагает предварительную обработку данных, к примеру, увеличение масштаба изображения. Улучшение изображения входит в число наиболее простых и впечатляющих направлений предварительной обработки. Как правило, за методами улучшения информативности изображений определена задача поиска плохо различимых пикселей или увеличения контрастности на исходном изображении . Одним из часто используемых методов улучшения информативности изображений является усиление контраста изображения, так как усиливаются границы объекта интереса. Нужно учесть, что улучшение качества изображения - это в определенной степени субъективная задача в обработке изображений. Восстановление изображений - это задача также относится к повышению визуального качества данных. Методы восстановления изображений опираются на математические и вероятностные модели деформации графических данных. Обработку изображений как этап следует отделять от понятия обработки изображения как всего процесса изменений изображения и получения некоторых данных. Сегментация или процесс выделения объектов интереса делит изображение на составляющие объекты или части. Автоматизированное выделение объектов интереса является в определенной степени сложной задачей цифровой обработки изображений. Слишком детализированная сегментация делает процесс обработки изображения затруднительным, если необходимо выделить объекты интереса. Но некорректная или недостаточно детализированная сегментация в большинстве задач приводит к ошибкам на заключительном этапе обработки изображений. Представление и описание графических данных, как правило, следуют за этапом выделения объектов интереса на изображении, на выходе которого в большинстве случаев имеются необработанные пиксели, образующие границы области или формируют все пиксели областей. При таких вариантах требуется преобразование данных в вид, доступный для компьютерного анализа. Распознавание образов является процессом, который определяет к какому-либо объекту идентификатор (например, «лучевая кость») на основании его описаний . Определим взаимосвязь базы знаний с модулями обработки изображений. База знаний (то есть информация о проблемной области) некоторым образом зашифрована внутри самой системы обработки изображений. Это знание может быть достаточно простым, как, например, детальное указание объектов изображения, где должна находиться зона интереса. Такое знание дает возможность ограничения области поиска. База знаний управляет работой каждого модуля обработки и их взаимодействием, что отражено на рис. 1 стрелками, направленными в две стороны между модулями и базой знаний. Сохранение и печать результатов часто также требует использования специальных методов обработки изображений. Недостаток этих этапов обработки изображения в системе обработки медицинских изображений заключается в том, то, что ошибки, созданные на первых этапах обработки, к примеру при вводе или выделения объектов интереса на изображении, могут привести к невозможности корректной классификации. Обработка данных производится строго последовательно, и в большинстве случаев отсутствует возможность возвращения на предыдущие этапы обработки, даже если ранее были получены некорректные результаты . Методы на этапе предварительной обработки достаточно разнообразны - выделение объектов интереса, их масштабирование, цветовая коррекция, корректировка пространственного разрешения, изменение контрастности и т.п. Одно из приоритетных действий на этапе предварительной обработки изображения - это корректировка контрастности и яркости. При использовании соответствующих масок возможно объединить два этапа (фильтрация и предварительная обработка) для увеличения скорости анализа данных. Заключительный результат анализа изображений в большинстве случаев определен уровнем качества сегментации, а степень детализации объектов интереса зависит от конкретной поставленной задачи . По этой причине не разработан отдельный метод или алгоритм, подходящий для решения всех задач выделения объектов интереса. Оконтуривание областей предназначено для выделения на изображениях объектов с заданными свойствами. Данные объекты, как правило, соответствуют объектам или их частям, которые маркируют диагносты. Итогом оконтуривания является бинарное или иерархическое (мультифазное) изображение, где каждый уровень изображения соответствует определенному классу выделенных объектов. Сегментация - это сложный этап в обработке и анализе медицинских данных биологических тканей, поскольку необходимо оконтуривать области, которые соответствуют разным объектам или структурам на гистологических уровнях: клеткам, органоидам, артефактам и т.д. Это объясняется высокой вариабельностью их параметров, низким уровнем контрастности анализируемых изображений и сложной геометрической взаимосвязью объектов. В большинстве случаях для получения максимально эффективного результата необходимо последовательно использовать разные методы сегментации объектов интереса на изображении. К примеру, для определения границ объекта интереса применяется метод морфологического градиента, после которого для областей, которые подходят незначительным перепадам характеристик яркости, проводится пороговая сегментация . Для обработки изображений, у которых несвязанные однородные участки различны по средней яркости, был выбран метод сегментации Canny, исследования проводятся на клиническом примере. При распознавании реальных клинических изображений моделирование плохо применимо. Большое значение имеет практический опыт и экспертные заключения об итоге анализа изображений. Для тестового изображения выбран снимок компьютерной томографии, где в явном виде присутствует объект интереса, представленный на рис. 2.

Рис. 2. Снимок компьютерной томографии с объектом интереса
Для реализации сегментирования используем метод Canny . Такой подход устойчив к шуму и демонстрирует в большинстве случаев лучшие результаты по отношению к другим методам. Метод Canny включает в себя четыре этапа:
1) предобработка - размытие изображения (производим уменьшение дисперсии аддитивного шума);
2) проведение дифференцирования размытого изображения и последующее вычисление значений градиента по направлениям x и y;
3) реализация не максимального подавления на изображении;
4) пороговая обработка изображения .
На первом этапе алгоритма Canny происходит сглаживание изображения с помощью маски фильтром Гаусса. Уравнение распределения Гаусса в N измерениях имеет вид
или в частном случае для двух измерений
![]() (2)
(2)
где r - это радиус размытия, r 2 = u 2 + v 2 ; σ - стандартное отклонение распределения Гаусса.
Если используем 2 измерения, то эта формула задает поверхность концентрических окружностей, имеющих распределение Гаусса от центральной точки. Пиксели с распределением, отличным от нуля, используются для задания матрицы свертки, применяемого к исходному изображению. Значение каждого пикселя становится средневзвешенным для окрестности. Начальное значение пикселя принимает максимальный вес (имеет максимальное Гауссово значение), а соседние пиксели принимают минимальные веса, в зависимости от расстояния до них . Теоретически распределение в каждой точке изображения должно быть ненулевым, что следует расчету весовых коэффициентов для каждого пикселя изображения. Но практически при расчёте дискретного приближения функции Гаусса не учитываются пиксели на расстоянии > 3σ, поскольку оно достаточно мало. Таким образом, программе, обрабатывающей изображение, необходимо рассчитать матрицу ×, чтобы дать гарантию достаточной точности приближения распределения Гаусса .
Результаты исследования и их обсуждение
Результат работы фильтра Гаусса при данных равных 5 для размера маски гаусса и 1,9 значении параметра σ - стандартного отклонения распределения Гаусса, представлен на рис. 3. Следующим шагом осуществляется поиск градиента области интереса при помощи свертки сглаженного изображения с производной от функции Гаусса в вертикальном и горизонтальном направлениях вектора.
Применим оператор Собеля для решения данной задачи . Процесс базируется на простом перемещении маски фильтра от пикселя к пикселю изображения. В каждом пикселе (x, y) отклик фильтра вычисляется с предварительно определённых связей. В результате происходит первоначальное выделение краев. Следующим шагом происходит сравнение каждого пикселя с его соседями вдоль направления градиента и вычисляется локальный максимум. Информация о направлении градиента необходима для того, чтобы удалять пиксели рядом с границей, не разрывая саму границу вблизи локальных максимумов градиента, которое значит, что пикселями границ определяются точки, в которых достигается локальный максимум градиента в направлении вектора градиента. Такой подход позволяет существенно снизить обнаружение ложных краев и обеспечивает толщину границы объекта в один пиксель, что эмпирически подтверждается программной реализацией алгоритма сегментирования среза брюшной полости на снимке компьютерной томографии, представленного ниже на рис. 4.
Следующий шаг - использование порога, для определения нахождения границы в каждом заданном пикселе изображения. Чем меньше порог, тем больше границ будет находиться в объекте интереса, но тем более результат будет восприимчив к шуму, и оконтуривать лишние данные изображения. Высокий порог может проигнорировать слабые края области или получит границу несколькими областями. Оконтуривание границ применяет два порога фильтрации: если значение пикселя выше верхней границы - он принимает максимальное значение (граница считается достоверной), если ниже - пиксель подавляется, точки со значением, попадающим в диапазон между порогов, принимают фиксированное среднее значение. Пиксель присоединяется к группе, если он соприкасается с ней по одному из восьми направлений. Среди достоинств метода Canny можно считать то, что при обработке изображения осуществляется адаптация к особенностям сегментирования. Это достигается через ввод двухуровневого порога отсечения избыточных данных. Определяются два уровня порога, верхний - p high и нижний - p low , где p high > p low . Значения пикселей выше значения p high обозначаются как соответствующие границе (рис. 5).

Рис. 3. Применение фильтра Гаусса на компьютерной томограмме с объектом интереса

Рис. 4. Подавления не-максимумов на сегментируемом изображении

Рис. 5. Применение алгоритма сегментации Canny c разными значениями уровней порога
Практика показывает, что имеется некоторый интервал на шкале уровней порога чувствительности, при котором значение площади объекта интереса фактически неизменимое, но при этом существует определенный пороговый уровень, после которого отмечается «срыв» метода оконтуривания и итог выделения областей интереса становится неопределенным . Этот недостаток алгоритма, который можно компенсировать объединением алгоритма Canny с преобразованием Хафа для поиска окружностей. Сочетание алгоритмов позволяет максимально четко выделять объекты исследования, а также устранять разрывы в контурах .
Выводы
Таким образом, решена задача формулирования типовых характеристик патологических объектов на медицинских изображениях, что даст возможность в дальнейшем проводить оперативный анализ данных по конкретным патологиям. Важными параметрами для определения оценки качества сегментации являются вероятности ложной тревоги и пропуска - отказа. Эти параметры определяют применение автоматизации метода анализа. Сегментация при решении задачи классификации и распознавания объектов на изображениях является одной из первостепенных. Достаточно хорошо исследованы и применяются методы оконтуривания, базирующиея на сегментировании границ областей - Sobel, Canny, Prewit, Laplassian. Такой подход определен тем, что концентрация внимания человека при анализе изображений фокусируется зачастую на границах между более или менее однородными по яркости зонами. Исходя из этого, контуры часто выполняют задачу основы определения различных характеристик для интерпретирования изображений и объектов на них. Основная задача алгоритмов сегментирования зон интересов - это построение бинарного изображения, которое содержит замкнутые структурные области данных на изображении. Относительно к медицинским изображениям данными областями выступают границы органов, вены, МКЦ, а также опухоли. Разработанные принципы компьютерного автоматизированного анализа медицинских изображений эффективно используются как для оперативных задач медицинской диагностики специализированного онкологического учреждения, так и в учебных целях.
Исследовано при поддержке программы «Дальний Восток», грант № 15-I-4-014o.
Рецензенты:
Косых Н.Э., д.м.н., профессор, главный научный сотрудник, ФГБУН «Вычислительный центр» ДВО РАН, г. Хабаровск;
Левкова Е.А., д.м.н., профессор, ГОУ ВПО «Дальневосточный государственный университет путей сообщения», г. Хабаровск.
Библиографическая ссылка
Дороничева А.В., Савин С.З. МЕТОД СЕГМЕНТАЦИИ МЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ // Фундаментальные исследования. – 2015. – № 5-2. – С. 294-298;URL: http://fundamental-research.ru/ru/article/view?id=38210 (дата обращения: 06.04.2019). Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
Этим летом мне посчастливилось попасть на летнюю стажировку в компанию Itseez
. Мне было предложено исследовать современные методы, которые позволили бы выделить местоположения объектов на изображении. В основном такие методы опираются на сегментацию, поэтому я начала свою работу со знакомства с этой областью компьютерного зрения.
Сегментация изображения
- это разбиение изображения на множество покрывающих его областей. Сегментация применяется во многих областях, например, в производстве для индикации дефектов при сборке деталей, в медицине для первичной обработки снимков, также для составления карт местности по снимкам со спутников. Для тех, кому интересно разобраться, как работают такие алгоритмы, добро пожаловать под кат. Мы рассмотрим несколько методов из библиотеки компьютерного зрения OpenCV
.
Алгоритм сегментации по водоразделам (WaterShed)


Алгоритм работает с изображением как с функцией от двух переменных f=I(x,y) , где x,y – координаты пикселя:



Значением функции может быть интенсивность или модуль градиента. Для наибольшего контраста можно взять градиент от изображения. Если по оси OZ откладывать абсолютное значение градиента, то в местах перепада интенсивности образуются хребты, а в однородных регионах – равнины. После нахождения минимумов функции f , идет процесс заполнения “водой”, который начинается с глобального минимума. Как только уровень воды достигает значения очередного локального минимума, начинается его заполнение водой. Когда два региона начинают сливаться, строится перегородка, чтобы предотвратить объединение областей . Вода продолжит подниматься до тех пор, пока регионы не будут отделяться только искусственно построенными перегородками (рис.1).



Рис.1. Иллюстрация процесса заполнения водой
Такой алгоритм может быть полезным, если на изображении небольшое число локальных минимумов, в случае же их большого количества возникает избыточное разбиение на сегменты. Например, если непосредственно применить алгоритм к рис. 2, получим много мелких деталей рис. 3.

Рис. 2. Исходное изображение

Рис. 3. Изображение после сегментации алгоритмом WaterShed
Как справиться с мелкими деталями?
Чтобы избавиться от избытка мелких деталей, можно задать области, которые будут привязаны к ближайшим минимумам. Перегородка будет строиться только в том случае, если происходит объединение двух регионов с маркерами, в противном случае будет происходить слияние этих сегментов. Такой подход убирает эффект избыточной сегментации, но требует предварительной обработки изображения для выделения маркеров, которые можно обозначить интерактивно на изображении рис. 4, 5.

Рис. 4. Изображение с маркерами

Рис. 5. Изображение после сегментации алгоритмом WaterShed
с использованием маркеров
Если требуется действовать автоматически без вмешательства пользователя, то можно использовать, например, функцию findContours() для выделения маркеров, но тут тоже для лучшей сегментации мелкие контуры следует исключить рис. 6., например, убирая их по порогу по длине контура. Или перед выделением контуров использовать эрозию с дилатацией, чтобы убрать мелкие детали.

Рис. 6. В качестве маркеров использовались контуры, имеющие длину выше определенного порога
В результате работы алгоритма мы получаем маску с сегментированным изображением, где пиксели одного сегмента помечены одинаковой меткой и образуют связную область. Основным недостатком данного алгоритма является использование процедуры предварительной обработки для картинок с большим количеством локальных минимумов (изображения со сложной текстурой и с обилием различных цветов).
Mat image = imread("coins.jpg", CV_LOAD_IMAGE_COLOR);
// выделим контуры
Mat imageGray, imageBin;
cvtColor(image, imageGray, CV_BGR2GRAY);
threshold(imageGray, imageBin, 100, 255, THRESH_BINARY);
std::vector
Алгоритм сегментации MeanShift
MeanShift группирует объекты с близкими признаками. Пиксели со схожими признаками объединяются в один сегмент, на выходе получаем изображение с однородными областями.

Например, в качестве координат в пространстве признаков можно выбрать координаты пикселя (x, y) и компоненты RGB пикселя. Изобразив пиксели в пространстве признаков, можно заметить сгущения в определенных местах.

Рис. 7. (a) Пиксели в двухмерном пространстве признаков. (b) Пиксели, пришедшие в один локальный максимум, окрашены в один цвет. (с) - функция плотности, максимумы соответствуют местам наибольшей концентрации пикселей. Рисунок взят из статьи .
Чтобы легче было описывать сгущения точек, вводится функция плотности
: 
– вектор признаков i
-ого пикселя, d
- количество признаков, N
- число пикселей, h
- параметр, отвечающий за гладкость, - ядро. Максимумы функции расположены в точках сгущения пикселей изображения в пространстве признаков. Пиксели, принадлежащие одному локальному максимуму, объединяются в один сегмент. Получается, чтобы найти к какому из центров сгущения относится пиксель, надо шагать по градиенту для нахождения ближайшего локального максимума.
Оценка градиента от функции плотности
Для оценки градиента функции плотности можно использовать вектор среднего сдвига ![]()
В качестве ядра в OpenCV используется ядро Епанечникова :
- это объем d
-мерной сферы c единичным радиусом.
 означает, что сумма идет не по всем пикселям, а только по тем, которые попали в сферу радиусом h
с центром в точке, куда указывает вектор в пространстве признаков . Это вводится специально, чтобы уменьшить количество вычислений. - объем d
-мерной сферы с радиусом h, Можно отдельно задавать радиус для пространственных координат и отдельно радиус в пространстве цветов. - число пикселей, попавших в сферу. Величину
означает, что сумма идет не по всем пикселям, а только по тем, которые попали в сферу радиусом h
с центром в точке, куда указывает вектор в пространстве признаков . Это вводится специально, чтобы уменьшить количество вычислений. - объем d
-мерной сферы с радиусом h, Можно отдельно задавать радиус для пространственных координат и отдельно радиус в пространстве цветов. - число пикселей, попавших в сферу. Величину  можно рассматривать как оценку значения в области .
можно рассматривать как оценку значения в области .

Поэтому, чтобы шагать по градиенту, достаточно вычислить значение ![]() - вектора среднего сдвига. Следует помнить, что при выборе другого ядра вектор среднего сдвига будет выглядеть иначе.
- вектора среднего сдвига. Следует помнить, что при выборе другого ядра вектор среднего сдвига будет выглядеть иначе.
При выборе в качестве признаков координат пикселей и интенсивностей по цветам в один сегмент будут объединяться пиксели с близкими цветами и расположенные недалеко друг от друга. Соответственно, если выбрать другой вектор признаков, то объединение пикселей в сегменты уже будет идти по нему. Например, если убрать из признаков координаты, то небо и озеро будут считаться одним сегментом, так как пиксели этих объектов в пространстве признаков попали бы в один локальный максимум.
Если объект, который хотим выделить, состоит из областей, сильно различающихся по цвету, то MeanShift не сможет объединить эти регионы в один, и наш объект будет состоять из нескольких сегментов. Но зато хорошо справиться с однородным по цвету предметом на пестром фоне. Ещё MeanShift используют при реализации алгоритма слежения за движущимися объектами .
Пример кода для запуска алгоритма:
Mat image = imread("strawberry.jpg", CV_LOAD_IMAGE_COLOR);
Mat imageSegment;
int spatialRadius = 35;
int colorRadius = 60;
int pyramidLevels = 3;
pyrMeanShiftFiltering(image, imageSegment, spatialRadius, colorRadius, pyramidLevels);
imshow("MeanShift", imageSegment);
waitKey(0);
Результат:
Рис. 8. Исходное изображение

Рис. 9. После сегментации алгоритмом MeanShift
Алгоритм сегментации FloodFill
С помощью FloodFill (заливка или метод «наводнения») можно выделить однородные по цвету регионы. Для этого нужно выбрать начальный пиксель и задать интервал изменения цвета соседних пикселей относительно исходного. Интервал может быть и несимметричным. Алгоритм будет объединять пиксели в один сегмент (заливая их одним цветом), если они попадают в указанный диапазон. На выходе будет сегмент, залитый определенным цветом, и его площадь в пикселях.Такой алгоритм может быть полезен для заливки области со слабыми перепадами цвета однородным фоном. Одним из вариантов использования FloodFill
может быть выявление поврежденных краев объекта. Например, если, заливая однородные области определенным цветом, алгоритм заполнит и соседние регионы, то значит нарушена целостность границы между этими областями. Ниже на изображении можно заметить, что целостность границ заливаемых областей сохраняется:

Рис. 10, 11. Исходное изображение и результат после заливки нескольких областей
А на следующих картинках показан вариант работы FloodFill в случае повреждения одной из границ в предыдущем изображении.


Рис. 12, 13. Иллюстрация работы FloodFill
при нарушение целостности границы между заливаемыми областями
Пример кода для запуска алгоритма:
Mat image = imread("cherry.jpg", CV_LOAD_IMAGE_COLOR);
Point startPoint;
startPoint.x = image.cols / 2;
startPoint.y = image.rows / 2;
Scalar loDiff(20, 20, 255);
Scalar upDiff(5, 5, 255);
Scalar fillColor(0, 0, 255);
int neighbors = 8;
Rect domain;
int area = floodFill(image, startPoint, fillColor, &domain, loDiff, upDiff, neighbors);
rectangle(image, domain, Scalar(255, 0, 0));
imshow("floodFill segmentation", image);
waitKey(0);
В переменную area
запишется количество “залитых" пикселей.
Результат: 

Алгоритм сегментации GrabCut
Это интерактивный алгоритм выделения объекта, разрабатывался как более удобная альтернатива магнитному лассо (чтобы выделить объект, пользователю требовалось обвести его контур с помощью мыши). Для работы алгоритма достаточно заключить объект вместе с частью фона в прямоугольник (grab). Сегментирование объекта произойдет автоматически (cut).

Могут возникнуть сложности при сегментации, если внутри ограничивающего прямоугольника присутствуют цвета, которые встречаются в большом количестве не только в объекте, но и на фоне. В этом случае можно поставить дополнительные метки объекта (красная линия) и фона (синяя линия).



Рассмотрим идею алгоритма. За основу взят алгоритм интерактивной сегментации GraphCut, где пользователю надо поставить маркеры на фон и на объект. Изображение рассматривается как массив ![]() . Z
- значения интенсивности пикселей, N
-общее число пикселей. Для отделения объекта от фона алгоритм определяет значения элементов массива прозрачности , причем может принимать два значения, если = 0
, значит пиксель принадлежит фону, если= 1
, то объекту. Внутренний параметр содержит гистограмму распределения интенсивности переднего плана и гистограмму фона:
. Z
- значения интенсивности пикселей, N
-общее число пикселей. Для отделения объекта от фона алгоритм определяет значения элементов массива прозрачности , причем может принимать два значения, если = 0
, значит пиксель принадлежит фону, если= 1
, то объекту. Внутренний параметр содержит гистограмму распределения интенсивности переднего плана и гистограмму фона:
.
Задача сегментации - найти неизвестные . Рассматривается функция энергии:
Причем минимум энергии соответствует наилучшей сегментации.
V (a, z)
- слагаемое отвечает за связь между пикселями. Сумма идет по всем парам пикселей, которые являются соседями, dis(m,n)
- евклидово расстояние. ![]() отвечает за участие пар пикселей в сумме, если a n = a m
, то эта пара не будет учитываться.
отвечает за участие пар пикселей в сумме, если a n = a m
, то эта пара не будет учитываться. ![]() - отвечает за качество сегментации, т.е. разделение объекта от фона.
- отвечает за качество сегментации, т.е. разделение объекта от фона.
Найдя глобальный минимум функции энергии E , получим массив прозрачности . Для минимизации функции энергии, изображение описывается как граф и ищется минимальный разрез графа. В отличие от GraphCut в алгоритме GrabCut пиксели рассматриваются в RGB пространстве, поэтому для описания цветовой статистики используют смесь гауссиан (Gaussian Mixture Model - GMM). Работу алгоритма GrabCut можно посмотреть, запустив сэмпл OpenCV
Cегментация означает выделение областей однородных по какому-либо критерию, например по яркости. Математическая формулировка задачи сегментации может иметь следующий вид .
Пусть
-функция
яркости анализируемого изображения;
X
– конечное
подмножество плоскости на котором
определена
 ;
; - разбиение
X
на
K
непустых
связных подмножеств
- разбиение
X
на
K
непустых
связных подмножеств
 LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
 удовлетворяет критерию однородности.
удовлетворяет критерию однородности.
Сегментацией
изображения
 по предикату
LP
называется
разбиение
по предикату
LP
называется
разбиение

 ,
удовлетворяющее условиям:
,
удовлетворяющее условиям:
а)
 ;
;
б)
 ;
;
в)
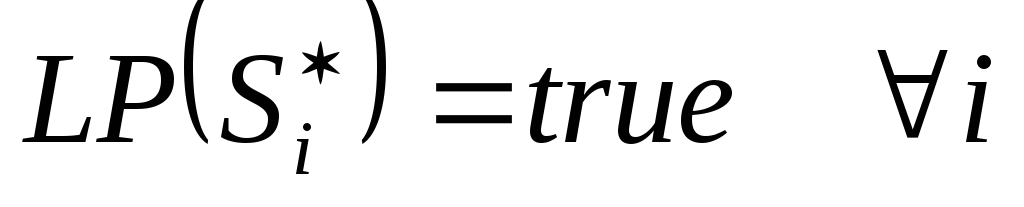 ;
;
г) смежные области.
Условия а) и б) означают, что каждая точка изображения должна быть единственным образом отнесена к некоторой области, в) определяет тип однородности получаемых областей и, наконец, г) выражает свойство “максимальности” областей разбиения.
Предикат LP называется предикатом однородности и может быть записан в виде:
 (1)
(1)
где
 -отношение
эквивалентности;
-отношение
эквивалентности;
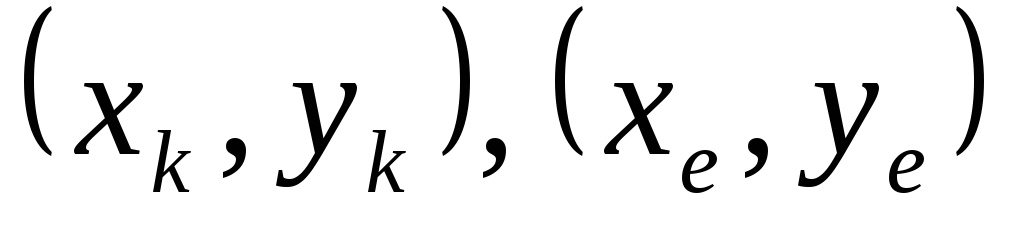 - произвольные точки из
- произвольные точки из
 .Таким образом,
сегментацию можно рассматривать как
оператор вида:
.Таким образом,
сегментацию можно рассматривать как
оператор вида:
где
 -функции,
определяющие исходное и сегментированное
изображение соответственно;
-функции,
определяющие исходное и сегментированное
изображение соответственно;
 -метка i-
й
области.
-метка i-
й
области.
Существуют
два общих подхода к решению задачи
сегментации
, которые
базируются на альтернативных
методологических концепциях. Первый
подход основан на идее “разрывности”
свойств
точек изображения при переходе от одной
области к другой. Этот подход сводит
задачу сегментации к задаче выделения
границ областей. Успешное решение
последней позволяет, вообще говоря,
идентифицировать и сами области, и их
границы. Второй подход реализует
стремление выделить точки изображения,
однородные по своим локальным свойствам,
и объединить их в область, которой позже
будет присвоено имя или смысловая метка.
В литературе первый подход называют
сегментацией
путем выделения границ областей
,
а второй – сегментацией
путем разметки точек области
.
Данное выше математическое определение
задачи позволяет характеризовать эти
подходы в терминах предиката однородности
LP
.
В первом
случае в качестве LP
должен
выступать предикат, принимающий истинные
значение на граничных точках областей
и ложные значения на внутренних точках.
Однако можно отметить существенное
ограничение этого подхода, состоящее
в том, что разбиение
 является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
Для второго подхода предикат LP может иметь вид, определяемый соотношением (5.1). Указанные выше подходы порождают конкретные методы и алгоритмы решения задачи сегментации.
Метод сегментации на основе пороговой обработки
Пороговая обработка изображения означает преобразование его функции яркости оператором вида
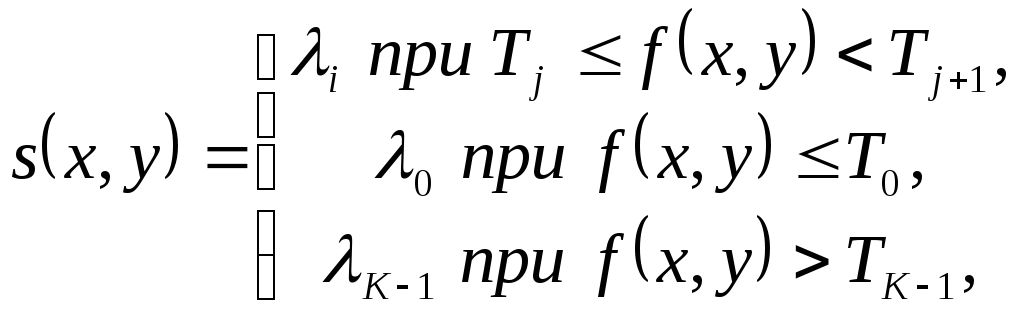
где
s(x,y)
– сегментированное
изображение;
K
–
число
областей сегментации;
 - метки сегментированных областей;
- метки сегментированных областей;
 - величины порогов, упорядоченные так,
что
- величины порогов, упорядоченные так,
что
 .
.
В частном случае при K= 2 пороговая обработка предусматривает использование единственного порога T . При назначении порогов применяют, как правило, гистограмму значений фунции яркости изображения.
Алгоритм сегментации на основе пороговой обработки на псевдокоде
Вход: mtrIntens – исходная матрица полутонового изображения;
l, r – пороги по гистограмме
Выход: mtrIntensNew – матрица сегментированного изображения
for i:=0 to l-1 do
for i:=l to r do
for i:=r+1 to 255 do
LUT[i]=255;
for i:=1 to 100 do
for j:=1 to 210 do
mtrIntensNew:=LUT]
Пороговая обработка является одним из основных методов сегментации изображений, благодаря интуитивно понятным свойствам. Этот метод ориентирован на обработку изображений, отдельные однородные области которых отличаются средней яркостью. Самым распространенным методом сегментации путем пороговой обработки является бинарная сегментация, то есть когда в нашем распоряжении имеется два типа однородных участков.
В этом случае изображение обрабатывается по пикселям и преобразование каждого пикселя входного изображения в выходное определяется из соотношения:

где - параметр обработки, называемый порогом, и - уровни выходной яркости. Обработка по пикселям, положение которых на изображении не играет никакой роли, называется точечной . Уровни и играют роль меток. По ним определяют, к какому типу отнести данную точку: к H0 или к H1. Или говорят, что H0 состоит из фоновых точек, а H1 из точек интереса . Как правило, уровни и соответствуют уровням белого и черного. Будем называть классы H1 (он же класс интереса) классом объекта, а класс H0 классом фона.
Естественно сегментация может быть не только бинарной и в таком случае существующих классов больше, чем два. Такой вид сегментации называется многоуровневым. Результирующее изображение не является бинарным, но оно состоит из сегментов различной яркости. Формально данную операцию можно записать следующим образом:

где - количество уровней, а - классы изображения. В таком случае для каждого из классов должен быть задан соответствующий порог, который бы отделял эти классы между собой. Бинарные изображения легче хранить и обрабатывать, чем изображения, в которых имеется много уровней яркости .
Самым сложным в пороговой обработке является сам процесс определения порога. Порог часто записывают как функцию, имеющую вид:
где - изображение, а - некоторая характеристика точки изображения, например, средняя яркость в окрестности с центром в этой точке.
Если значение порога зависит только от, то есть одинаково для всех точек изображения, то такой порог называют глобальным. Если порог зависит от пространственных координат, то такой порог называется локальным. Если зависит от характеристики, то тогда такой порог называется адаптивным. Таким образом, обработка считается глобальной, если она относится ко всему изображению в целом, а локальной, если она относится к некоторой выделенной области.
Помимо перечисленных разграничений алгоритмов существует еще множество методов. Многие из них являются просто совокупностью других, но большинство из них, так или иначе, базируются на анализе гистограммы исходного изображения, однако есть и принципиально другие подходы, которые не затрагивают анализ гистограмм в прямом виде или переходят от них к анализу некоторых других функций.
Редактирование изображений и создание коллажей было бы весьма захватывающим процессом, если бы не приходилось тратить бо́льшую часть времени на кропотливую разметку объектов. Задача еще усложняется, когда границы объектов размыты или присутствует прозрачность. Инструменты “Photoshop”, такие как «магнитное лассо» и «волшебная палочка», не очень интеллектуальны, поскольку ориентируются лишь на низкоуровневые признаки изображения. Они возвращают жёсткие (Hard) границы, которые затем нужно исправлять вручную. Подход Semantic Soft Segmentation от исследователей Adobe помогают решить эту непростую задачу, разделяя изображение на слои, соответствующие семантически значимым областям, и добавляя плавные переходы на краях.
«Мягкая» сегментация
Группа исследователей из лаборатории CSAIL в MIT и швейцарского университета ETH Zürich, работающая под руководством Ягыза Аксоя, предложила подойти к этой проблеме, основываясь на спектральной сегментацией, добавив к ней современные достижения глубокого обучения. С помощью текстурной и цветовой информации, а также высокоуровневых семантических признаков, извлечённых , по изображению строится граф специального вида. Затем по этому графу строится матрица Кирхгофа (Laplacian matrix). Используя спектральное разложение этой матрицы, алгоритм генерирует мягкие контуры объектов. Полученное с помощью собственных векторов разбиение изображения на слои можно затем использовать для редактирования.
Обзор предложенного подхода
Описание модели
Рассмотрим метод создания семантически значимых слоёв пошагово:
1. Спектральная маска. Предложенный подход продолжает работу Левина и его коллег, которые впервые использовали матрицу Кирхгофа в задаче автоматического построения маски. Они строили матрицу L, которая задаёт попарное сходство между пикселями в некоторой локальной области. С помощью этой матрицы они минимизируют квадратичный функционал αᵀLα с заданными пользователем ограничениями, где α задаёт вектор значений прозрачности для всех пикселей данного слоя. Каждый мягкий контур является линейной комбинацией K собственных векторов, соответствующих наименьшим собственным значениям L, которая максимизирует так называемую разреженность маски.
2. Цветовая близость. Для вычисления признаков нелокальной цветовой близости исследователи генерируют 2500 суперпикселей и оценивают близость между каждым суперпикселем и всеми суперпикселями в окрестности радиусом 20% размера изображения. Использование нелокальной близости гарантирует, что области с очень похожими цветами останутся связными в сложных сценах, подобных изображённой ниже.
 Нелокальная цветовая близость
Нелокальная цветовая близость
3. Семантическая близость. Эта стадия позволяет выделять семантически связные области изображения. Семантическая близость поощряет объединение пикселей, которые принадлежат одному объекту сцены, и штрафует за объединение пикселей разных объектов. Здесь исследователи используют предыдущие достижения в области распознавания образов и вычисляют для каждого пикселя вектор признаков, коррелирующий с объектом, в который входит данный пиксель. Векторы признаков вычисляются с помощью нейросети, о чём мы поговорим далее более подробно. Семантическая близость, как и цветовая, определяется на суперпикселях. Однако, в отличие от цветовой близости, семантическая близость связывает только ближайшие суперпиксели, поощряя создание связных объектов. Сочетание нелокальной цветовой близости и локальной семантической близости позволяет создать слои, которые покрывают разъединённые в пространстве изображения фрагмента одного семантически связанного объекта (например, растительность, небо, другие типы фона).
 Семантическая близость
Семантическая близость
4. Создание слоёв. На этом шаге с помощью вычисленных ранее близостей строится матрица L. Из этой матрицы извлекаются собственные векторы, соответствующие 100 наименьшим собственным значениям, а затем применяется алгоритм разреживания, который извлекает из них 40 векторов, по которым строятся слои. Затем количество слоёв ещё раз уменьшается с помощью алгоритма кластеризации k-means при k = 5. Это работает лучше, чем простое разреживание 100 собственных векторов до пяти, поскольку такое сильное сокращение размерности делает задачу переопределённой. Исследователи выбрали итоговое число контуров равным 5 и утверждают, что это разумное число для большинства изображений. Тем не менее, это число можно изменить вручную в зависимости от обрабатываемого изображения.
 Мягкие контуры до и после группировки
Мягкие контуры до и после группировки 5. Семантические векторы признаков. Для вычисления семантической близости использовались векторы признаков, посчитанные с помощью нейросети. Основой нейросети стала DeepLab-ResNet-101, обученная на задаче предсказания метрики. При обучении поощрялась максимизация L2-расстояния между признаками разных объектов. Таким образом, нейросеть минимизирует расстояние между признаками, соответствующими одному классу, и максимизирует расстояние в другом случае.
Качественное сравнение со схожими методами
Изображения, приведённые ниже, показывают результаты работы предложенного подхода (подписанные как «Our result») в сравнении с результатами наиболее близкого подхода мягкой сегментации - спектрального метода построения маски - и двумя state-of-the-art методами семантической сегментации: методом обработки сцен PSPNet и методом сегментации объектов Mask R-CNN.

 Качественные сравнения мягкой семантической сегментации с другими подходами
Качественные сравнения мягкой семантической сегментации с другими подходами Можно заменить, что PSPNet и Mask R-CNN склонны ошибаться на границах объектов, а мягкие контуры, построенные спектральным методом, часто заходят за границы объектов. При этом описанный метод полностью охватывает объект, не объединяя его с другими, и достигает высокой точности на краях, добавляя мягкие переходы, где это требуется. Однако стоит заметить, что семантические признаки, использованные в данном методе, не различают два разных объекта, принадлежащих к одному классу. В результате множественные объекты представлены на одном слое, что видно на примере изображений жирафов и коров.
Редактирование изображений с помощью мягких семантических контуров

Ниже приведено несколько примеров применения мягких контуров для редактирования изображений и создания коллажей. Мягкие контуры можно использовать для применения конкретных изменений к разным слоям: добавления размытия, изображающего движение поезда (2), раздельной цветовой коррекции для людей и для фона (5, 6), отдельной стилизации для воздушного шара, неба, ландшафта и человека (8). Конечно, то же самое можно сделать с помощью созданных вручную масок или классических алгоритмов выделения контура, но с автоматическим выделением семантически значимых объектов такое редактирование становится значительно проще.
 Использование мягкой семантической сегментации для редактирования изображений
Использование мягкой семантической сегментации для редактирования изображений
Заключение
Данный метод автоматически создаёт мягкие контуры, соответствующие семантически значимым областям изображения, используя смесь высокоуровневой информации от нейронной сети и низкоуровневых признаков. Однако у этого метода есть несколько ограничений. Во-первых, он относительно медленный: время обработки изображения с размерами 640 x 480–3–4 минуты. Во-вторых, этот метод не создаёт отдельные слои для разных объектов одного класса. И в-третьих, как показано ниже, этот метод может ошибиться на начальных этапах обработки в случаях, когда цвета объектов очень похожи (верхний пример), или во время объединения мягких контуров возле больших переходных областей (нижний пример).
 Случаи ошибок алгоритма
Случаи ошибок алгоритма
Тем не менее, мягкие контуры, созданные с помощью описанного метода, дают удобное промежуточное представление изображения, позволяющее тратить меньше времени и сил при редактировании изображений.